
New algorithm encourages robots to move more randomly to collect more diverse data for learning. In tests, robots started with no knowledge and then learned and correctly performed tasks within a single attempt. New model could improve safety and practicality of self-driving cars, delivery drones and more.
Tag Archives: AI News

Research Focus: Week of April 29, 2024
Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
NEW RESEARCH
Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions?
Informal natural language that describes code functionality, such as code comments or function documentation, may contain substantial information about a program’s intent. However, there is no guarantee that a program’s implementation aligns with its natural language documentation. In the case of a conflict, leveraging information in code-adjacent natural language has the potential to enhance fault localization, debugging, and code trustworthiness. However, this information is often underutilized, due to the inherent ambiguity of natural language which makes natural language intent challenging to check programmatically. The “emergent abilities” of large language models (LLMs) have the potential to facilitate the translation of natural language intent to programmatically checkable assertions. However, due to a lack of benchmarks and evaluation metrics, it is unclear if LLMs can correctly translate informal natural language specifications into formal specifications that match programmer intent—and whether such translation could be useful in practice.
In a new paper: Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions? (opens in new tab), researchers from Microsoft describe nl2postcond, the problem leveraging LLMs for transforming informal natural language to formal method postconditions, expressed as program assertions. The paper, to be presented at the upcoming ACM International Conference on the Foundations of Software Engineering (opens in new tab), introduces and validates metrics to measure and compare different nl2postcond approaches, using the correctness and discriminative power of generated postconditions. The researchers show that nl2postcond via LLMs has the potential to be helpful in practice by demonstrating that LLM-generated specifications can be used to discover historical bugs in real-world projects.
NEW RESEARCH
Semantically Aligned Question and Code Generation for Automated Insight Generation
People who work with data, like engineers, analysts, and data scientists, often must manually look through data to find valuable insights or write complex scripts to automate exploration of the data. Automated insight generation provides these workers the opportunity to immediately glean insights about their data and identify valuable starting places for writing their exploration scripts. Unfortunately, automated insights produced by LLMs can sometimes generate code that does not correctly correspond (or align) to the insight. In a recent paper: Semantically Aligned Question and Code Generation for Automated Insight Generation (opens in new tab), researchers from Microsoft leverage the semantic knowledge of LLMs to generate targeted and insightful questions about data and the corresponding code to answer those questions. Through an empirical study on data from Open-WikiTable (opens in new tab), they then show that embeddings can be effectively used for filtering out semantically unaligned pairs of question and code. The research also shows that generating questions and code together yields more interesting and diverse insights about data.
NEW RESEARCH
Explaining CLIP’s performance disparities on data from blind/low vision users
AI-based applications hold the potential to assist people who are blind or low vision (BLV) with everyday visual tasks. However, human assistance is often required, due to the wide variety of assistance needed and varying quality of images available. Recent advances in large multi-modal models (LMMs) could potentially address these challenges, enabling a new era of automated visual assistance. Yet, little work has been done to evaluate how well LMMs perform on data from BLV users.
In a recent paper: Explaining CLIP’s performance disparities on data from blind/low vision users (opens in new tab), researchers from Microsoft and the World Bank address this issue by assessing CLIP (opens in new tab), a widely-used LMM with potential to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, their results show that disability objects, like guide canes and Braille displays, are recognized significantly less accurately than common objects, like TV remote controls and coffee mugs—in some cases by up to 28 percentage points difference.
The researchers perform an analysis of the captions in three large-scale datasets that are commonly used to train models like CLIP and show that BLV-related content (such as guide canes) is rarely mentioned. This is a potential reason for the large performance gaps. The researchers show that a few-shot learning approach with as little as five example images of a disability object can improve its ability to recognize that object, holding the potential to mitigate CLIP’s performance disparities for BLV users. They then discuss other possible mitigations.
Spotlight: AI-POWERED EXPERIENCE
Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Opens in a new tab
NEW RESEARCH
Closed-Form Bounds for DP-SGD against Record-level Inference
Privacy of training data is a central consideration when deploying machine learning (ML) models. Models trained with guarantees of differential privacy (DP) provably resist a wide range of attacks. Although it is possible to derive bounds, or safe limits, for specific privacy threats solely from DP guarantees, meaningful bounds require impractically small privacy budgets, which results in a large loss in utility.
In a recent paper: Closed-Form Bounds for DP-SGD against Record-level Inference, researchers from Microsoft present a new approach to quantify the privacy of ML models against membership inference (inferring whether a data record is in the training data) and attribute inference (reconstructing partial information about a record) without the indirection through DP. They focus on the popular DP-SGD algorithm, which they model as an information theoretic channel whose inputs are the secrets that an attacker wants to infer (e.g., membership of a data record) and whose outputs are the intermediate model parameters produced by iterative optimization. They obtain closed-form bounds for membership inference that match state-of-the-art techniques but are orders of magnitude faster to compute. They also present the first algorithm to produce data-dependent bounds against attribute inference. Compared to bounds computed indirectly through numerical DP budget accountants, these bounds provide a tighter characterization of the privacy risk of deploying an ML model trained on a specific dataset. This research provides a direct, interpretable, and practical way to evaluate the privacy of trained models against inference threats without sacrificing utility.
Microsoft Research in the news
TIME100 Most Influential People in Health
TIME | May 2, 2024
Microsoft Research president Peter Lee is included as an innovator on the 2024 TIME100 Health list, TIME’s inaugural list of 100 individuals who most influenced global health this year.
Sanctuary AI Announces Microsoft Collaboration to Accelerate AI Development for General Purpose Robots
Sanctuary AI | May 1, 2024
Sanctuary AI and Microsoft are collaborating on the development of AI models for general purpose humanoid robots. Sanctuary AI will leverage Microsoft’s Azure cloud resources for their AI workloads.
Tiny but mighty: The Phi-3 small language models with big potential
Microsoft Source | April 23, 2024
LLMs create exciting opportunities for AI to boost productivity and creativity. But they require significant computing resources. Phi-3 models, which perform better than models twice their size, are now publicly available from Microsoft.
AI Is Unearthing New Drug Candidates, But It Still Needs Human Oversight
Drug Discovery Online | April 11, 2024
Drug Discovery Online published a contributed article from Junaid Bajwa discussing how recent advancements in AI offer the potential to streamline and optimize drug development in unprecedented ways.
How AI is helping create sustainable farms of the future
The Grocer | April 16, 2024
Ranveer Chandra authored an essay on how AI is helping create sustainable farms of the future for UK-based trade outlet, The Grocer.
The Future of AI and Mental Health
Psychiatry Online | April 16, 2024
Psychiatric News published an article featuring Q&A with Jina Suh, highlighting the important considerations for the use of AI technologies among psychiatrists and mental health professionals.
MatterGen’s Breakthroughs: How AI Shapes the Future of Materials Science
Turing Post | April 19, 2024
Turing Post covered MatterGen in an interview with Tian Xie. Learn more about this impactful generative model for inorganic materials design.
Machine Learning Street Talk interview with Chris Bishop
Machine Learning Street Talk | April 10, 2024
Chris Bishop joined Dr. Tim Scarfe for a wide-ranging interview on advances in deep learning and AI for science.
Opens in a new tab
The post Research Focus: Week of April 29, 2024 appeared first on Microsoft Research.

Revolutionize Customer Satisfaction with tailored reward models for your business on Amazon SageMaker
As more powerful large language models (LLMs) are used to perform a variety of tasks with greater accuracy, the number of applications and services that are being built with generative artificial intelligence (AI) is also growing. With great power comes responsibility, and organizations want to make sure that these LLMs produce responses that align with their organizational values and provide the same unique experience they always intended for their end-customers.
Evaluating AI-generated responses presents challenges. This post discusses techniques to align them with company values and build a custom reward model using Amazon SageMaker. By doing so, you can provide customized customer experiences that uniquely reflect your organization’s brand identity and ethos.
Challenges with out-of-the-box LLMs
Out-of-the-box LLMs provide high accuracy, but often lack customization for an organization’s specific needs and end-users. Human feedback varies in subjectivity across organizations and customer segments. Collecting diverse, subjective human feedback to refine LLMs is time-consuming and unscalable.
This post showcases a reward modeling technique to efficiently customize LLMs for an organization by programmatically defining rewards functions that capture preferences for model behavior. We demonstrate an approach to deliver LLM results tailored to an organization without intensive, continual human judgement. The techniques aim to overcome customization and scalability challenges by encoding an organization’s subjective quality standards into a reward model that guides the LLM to generate preferable outputs.
Objective vs. subjective human feedback
Not all human feedback is the same. We can categorize human feedback into two types: objective and subjective.
Any human being who is asked to judge the color of the following boxes would confirm that the left one is a white box and right one is a black box. This is objective, and there are no changes to it whatsoever.
Determining whether an AI model’s output is “great” is inherently subjective. Consider the following color spectrum. If asked to describe the colors on the ends, people would provide varied, subjective responses based on their perceptions. One person’s white may be another’s gray.
This subjectivity poses a challenge for improving AI through human feedback. Unlike objective right/wrong feedback, subjective preferences are nuanced and personalized. The same output could elicit praise from one person and criticism from another. The key is acknowledging and accounting for the fundamental subjectivity of human preferences in AI training. Rather than seeking elusive objective truths, we must provide models exposure to the colorful diversity of human subjective judgment.
Unlike traditional model tasks such as classification, which can be neatly benchmarked on test datasets, assessing the quality of a sprawling conversational agent is highly subjective. One human’s riveting prose is another’s aimless drivel. So how should we refine these expansive language models when humans intrinsically disagree on the hallmarks of a “good” response?
The key is gathering feedback from a diverse crowd. With enough subjective viewpoints, patterns emerge on engaging discourse, logical coherence, and harmless content. Models can then be tuned based on broader human preferences. There is a general perception that reward models are often associated only with Reinforcement Learning from Human Feedback (RLHF). Reward modeling, in fact, goes beyond RLHF, and can be a powerful tool for aligning AI-generated responses with an organization’s specific values and brand identity.
Reward modeling
You can choose an LLM and have it generate numerous responses to diverse prompts, and then your human labelers will rank those responses. It’s important to have diversity in human labelers. Clear labeling guidelines are critical. Without explicit criteria, judgments can become arbitrary. Useful dimensions include coherence, relevance, creativity, factual correctness, logical consistency, and more. Human labelers put these responses into categories and label them favorite to least favorite, as shown in the following example. This example showcases how different humans perceive these possible responses from the LLM in terms of their most favorite (labeled as 1 in this case) and least favorite (labeled as 3 in this case). Each column is labeled 1, 2, or 3 from each human to signify their most preferred and least preferred response from the LLM.
By compiling these subjective ratings, patterns emerge on what resonates across readers. The aggregated human feedback essentially trains a separate reward model on writing qualities that appeal to people. This technique of distilling crowd perspectives into an AI reward function is called reward modeling. It provides a method to improve LLM output quality based on diverse subjective viewpoints.
Solution overview
In this post, we detail how to train a reward model based on organization-specific human labeling feedback collected for various prompts tested on the base FM. The following diagram illustrates the solution architecture.
For more details, see the accompanying notebook.
Prerequisites
To successfully train a reward model, you need the following:
A large dataset with prompts and ranked responses from human labelers that reflects your organizational and end-user needs. For this post, we store the dataset in an Amazon Simple Storage Service (Amazon S3) bucket.
A small language model with a numerical head like OPT-2.7b, Falcon 7b (a decoder-only model of approximately 6 GB is good enough).
A mechanism to run distributed training. For this post, we use SageMaker.
An AWS Identity and Access Management (IAM) role associated with the Amazon SageMaker Studio user profile that has access to the S3 bucket holding the curated dataset. The standard SageMaker IAM role will suffice for this post. Refer to Amazon SageMaker Identity-Based Policy Examples for guidance on best practices and examples of identity-based policies for SageMaker.
A SageMaker domain. You can quickly spin up a SageMaker domain and set up a single user for launching the SageMaker Studio notebook environment you’ll need to complete the model training. For instructions on setting up your environment, see Quick onboard to Amazon SageMaker domain.
Launch SageMaker Studio
Complete the following steps to launch SageMaker Studio:
On the SageMaker console, choose Studio in the navigation pane.
On the Studio landing page, select the domain and user profile for launching Studio.
Choose Open Studio.
To launch SageMaker Studio, choose Launch personal Studio.
Let’s see how to create a reward model locally in a SageMaker Studio notebook environment by using a pre-existing model from the Hugging Face model hub.
Prepare a human-labeled dataset and train a reward model
When doing reward modeling, getting feedback data from humans can be expensive. This is because reward modeling needs feedback from other human workers instead of only using data collected during regular system use. How well your reward model behaves depends on the quality and amount of feedback from humans.
We recommend using AWS-managed offerings such as Amazon SageMaker Ground Truth. It offers the most comprehensive set of human-in-the-loop capabilities, allowing you to harness the power of human feedback across the machine learning (ML) lifecycle to improve the accuracy and relevancy of models. You can complete a variety of human-in-the-loop tasks with SageMaker Ground Truth, from data generation and annotation to model review, customization, and evaluation, either through a self-service or AWS-managed offering.
For this post, we use the IMDB dataset to train a reward model that provides a higher score for text that humans have labeled as positive, and a lower score for negative text.
We prepare the dataset with the following code:
The following example shows a sample record from the prepared dataset, which includes references to rejected and chosen responses. We have also embedded the input ID and attention mask for the chosen and rejected responses.
Load the pre-trained model
In this case, we use the OPT-1.3b (Open Pre-trained Transformer Language Model) model in Amazon SageMaker JumpStart from Hugging Face. If you want to do all of the training locally on your notebook instead of distributed training, you need to use an instance with enough accelerator memory. We run the following training on a notebook running on ml.g4dn.xlarge instance type:
Define the custom trainer function
In the following code snippet, we create a custom trainer that calculates how well a model is performing on a task:
It compares the model’s results for two sets of input data: one set that was chosen and another set that was rejected. The trainer then uses these results to figure out how good the model is at distinguishing between the chosen and rejected data. This helps the trainer adjust the model to improve its performance on the task. The CustomTrainer class is used to create a specialized trainer that calculates the loss function for a specific task involving chosen and rejected input sequences. This custom trainer extends the functionality of the standard Trainer class provided by the transformers library, allowing for a tailored approach to handling model outputs and loss computation based on the specific requirements of the task. See the following code:
The TrainingArguments in the provided code snippet are used to configure various aspects of the training process for an ML model. Let’s break down the purpose of each parameter, and how they can influence the training outcome:
output_dir – Specifies the directory where the trained model and associated files will be saved. This parameter helps organize and store the trained model for future use.
overwrite_output_dir – Determines whether to overwrite the output directory if it already exists. Setting this to True allows for reusing the same directory without manual deletion.
do_train – Indicates whether to perform training. If set to True, the model will be trained using the provided training dataset.
do_eval and do_predict – Control whether to perform evaluation and prediction tasks, respectively. In this case, both are set to False, meaning only training will be conducted.
evaluation_strategy – Defines when evaluation should be performed during training. Setting it to “no” means evaluation will not be done during training.
learning_rate – Specifies the learning rate for the optimizer, influencing how quickly or slowly the model learns from the data.
num_train_epochs – Sets the number of times the model will go through the entire training dataset during training. One epoch means one complete pass through all training samples.
per_device_train_batch_size – Determines how many samples are processed in each batch during training on each device (for example, GPU). A smaller batch size can lead to slower but more stable training.
gradient_accumulation_steps – Controls how often gradients are accumulated before updating the model’s parameters. This can help stabilize training with large batch sizes.
remove_unused_columns – Specifies whether unused columns in the dataset should be removed before processing, optimizing memory usage.
By configuring these parameters in the TrainingArguments, you can influence various aspects of the training process, such as model performance, convergence speed, memory usage, and overall training outcome based on your specific requirements and constraints.
When you run this code, it trains the reward model based on the numerical representation of subjective feedback you gathered from the human labelers. A trained reward model will give a higher score to LLM responses that humans are more likely to prefer.
Use the reward model to evaluate the base LLM
You can now feed the response from your LLM to this reward model, and the numerical score produced as output informs you of how well the response from the LLM is aligning to the subjective organization preferences that were embedded on the reward model. The following diagram illustrates this process. You can use this number as the threshold for deciding whether or not the response from the LLM can be shared with the end-user.
For example, let’s say we created an reward model to avoiding toxic, harmful, or inappropriate content. If a chatbot powered by an LLM produces a response, the reward model can then score the chatbot’s responses. Responses with scores above a pre-determined threshold are deemed acceptable to share with users. Scores below the threshold mean the content should be blocked. This lets us automatically filter chatbot content that doesn’t meet standards we want to enforce. To explore more, see the accompanying notebook.
Clean up
To avoid incurring future charges, delete all the resources that you created. Delete the deployed SageMaker models, if any, and stop the SageMaker Studio notebook you launched for this exercise.
Conclusion
In this post, we showed how to train a reward model that predicts a human preference score from the LLM’s response. This is done by generating several outputs for each prompt with the LLM, then asking human annotators to rank or score the responses to each prompt. The reward model is then trained to predict the human preference score from the LLM’s response. After the reward model is trained, you can use the reward model to evaluate the LLM’s responses against your subjective organizational standards.
As an organization evolves, the reward functions must evolve alongside changing organizational values and user expectations. What defines a “great” AI output is subjective and transforming. Organizations need flexible ML pipelines that continually retrain reward models with updated rewards reflecting latest priorities and needs. This space is continuously evolving: direct preference-based policy optimization, tool-augmented reward modeling, and example-based control are other popular alternative techniques to align AI systems with human values and goals.
We invite you to take the next step in customizing your AI solutions by engaging with the diverse and subjective perspectives of human feedback. Embrace the power of reward modeling to ensure your AI systems resonate with your brand identity and deliver the exceptional experiences your customers deserve. Start refining your AI models today with Amazon SageMaker and join the vanguard of businesses setting new standards in personalized customer interactions. If you have any questions or feedback, please leave them in the comments section.
About the Author
Dinesh Kumar Subramani is a Senior Solutions Architect based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning, and is member of technical field community with in Amazon. Dinesh works closely with UK Central Government customers to solve their problems using AWS services. Outside of work, Dinesh enjoys spending quality time with his family, playing chess, and exploring a diverse range of music.

Amazon Personalize launches new recipes supporting larger item catalogs with lower latency
Personalized customer experiences are essential for engaging today’s users. However, delivering truly personalized experiences that adapt to changes in user behavior can be both challenging and time-consuming. Amazon Personalize makes it straightforward to personalize your website, app, emails, and more, using the same machine learning (ML) technology used by Amazon, without requiring ML expertise. With the recipes—algorithms for specific uses cases—provided by Amazon Personalize, you can deliver a wide array of personalization, including product or content recommendations and personalized ranking.
Today, we are excited to announce the general availability of two advanced recipes in Amazon Personalize, User-Personalization-v2 and Personalized-Ranking-v2 (v2 recipes), which are built on the cutting-edge Transformers architecture to support larger item catalogs with lower latency.
In this post, we summarize the new enhancements, and guide you through the process of training a model and providing recommendations for your users.
Benefits of new recipes
The new recipes offer enhancements in scalability, latency, model performance, and functionality.
Enhanced scalability – The new recipes now support training with up to 5 million item catalogs and 3 billion interactions, empowering personalization for large catalogs and platforms with billions of usage events.
Lower latency – The lower inference latency and faster training times for large datasets of these new recipes can reduce the delay for your end-users.
Performance optimization – Amazon Personalize testing showed that v2 recipes improved recommendation accuracy by up to 9% and recommendation coverage by up to 1.8x compared to previous versions. A higher coverage means Amazon Personalize recommends more of your catalog.
Return item metadata in inference responses – The new recipes enable item metadata by default without extra charge, allowing you to return metadata such as genres, descriptions, and availability in inference responses. This can help you enrich recommendations in your user interfaces without extra work. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts. Providing more context to large language models can help them gain a deeper understanding of product attributes to generate more relevant content.
Highly automated operations – Our new recipes are designed to reduce your overhead for training and tuning the model. For example, Amazon Personalize simplifies training configuration and automatically selects the optimal settings for your custom models behind the scenes.
Solution overview
To use the User-Personalization-v2 and Personalized-Ranking-v2 recipes, you first need to set up Amazon Personalize resources. Create your dataset group, import your data, train a solution version, and deploy a campaign. For full instructions, see Getting started.
For this post, we follow the Amazon Personalize console approach to deploy a campaign. Alternatively, you can build the entire solution using the SDK approach. You can also get batch recommendations with an asynchronous batch flow. We use the MovieLens public dataset and User-Personalization-v2 recipe to show you the workflow.
Prepare the dataset
Complete the following steps to prepare your dataset:
Create a dataset group. Each dataset group can contain up to three datasets: users, items, and interactions, with the interactions dataset being mandatory for User-Personalization-v2 and Personalized-Ranking-v2.
Create an interactions dataset using a schema.
Import the interactions data to Amazon Personalize from Amazon Simple Storage Service (Amazon S3).
Train a model
After the dataset import job is complete, you can analyze data before training. Amazon Personalize Data analysis shows you statistics about your data as well as actions you can take to meet training requirements and improve recommendations.
Now you’re ready to train your model.
On the Amazon Personalize console, choose Dataset groups in the navigation pane.
Choose your dataset group.
Choose Create solutions.
For Solution name, enter your solution name.
For Solution type, select Item recommendation.
For Recipe, choose the new aws-user-personalization-v2 recipe.
In the Training configuration section, for Automatic training, select Turn on to maintain the effectiveness of your model by retraining it on a regular cadence.
Under Hyperparameter configuration, select Apply recency bias. Recency bias determines whether the model should give more weight to the most recent item interactions data in your interactions dataset.
Choose Create solution.
If you turned on automatic training, Amazon Personalize will automatically create your first solution version. A solution version refers to a trained ML model. When a solution version is created for the solution, Amazon Personalize trains the model backing the solution version based on the recipe and training configuration. It can take up to 1 hour for the solution version creation to start.
Under Custom resources in the navigation pane, choose Campaigns.
Choose Create campaign.
A campaign deploys a solution version (trained model) to generate real-time recommendations. Campaigns created with solutions trained on v2 recipes are automatically opted-in to include item metadata in recommendation results. You can choose metadata columns during an inference call.
Provide your campaign details and create your campaign.
Get recommendations
After you create or update your campaign, you can get a recommended list of items that users are more likely to interact with, sorted from highest to lowest.
Select the campaign and View details.
In the Test campaign results section, enter the User ID and choose Get recommendations.
The following table shows a recommendation result for a user that includes the recommended items, relevance score, and item metadata (Title and Genre).
Your User-Personalization-v2 campaign is now ready to feed into your website or app and personalize the journey of each of your customers.
Clean up
Make sure you clean up any unused resources you created in your account while following the steps outlined in this post. You can delete campaigns, datasets, and dataset groups via the Amazon Personalize console or using the Python SDK.
Conclusion
The new Amazon Personalize User-Personalization-v2 and Personalized-Ranking-v2 recipes take personalization to the next level with support of larger item catalogs, reduced latency, and optimized performance. For more information about Amazon Personalize, see the Amazon Personalize Developer Guide.
About the Authors
Jingwen Hu is a Senior Technical Product Manager working with AWS AI/ML on the Amazon Personalize team. In her spare time, she enjoys traveling and exploring local food.
Daniel Foley is a Senior Product Manager for Amazon Personalize. He is focused on building applications that leverage artificial intelligence to solve our customers’ largest challenges. Outside of work, Dan is an avid skier and hiker.
Pranesh Anubhav is a Senior Software Engineer for Amazon Personalize. He is passionate about designing machine learning systems to serve customers at scale. Outside of his work, he loves playing soccer and is an avid follower of Real Madrid.
Tianmin Liu is a senior software engineer working for Amazon personalize. He focuses on developing recommender systems at scale using various machine learning algorithms. In his spare time, he likes playing video games, watching sports, and playing the piano.
Abhishek Mangal is a software engineer working for Amazon Personalize. He works on developing recommender systems at scale using various machine learning algorithms. In his spare time, he likes to watch anime and believes One Piece is the greatest piece of storytelling in recent history.
Yifei Ma is a Senior Applied Scientist at AWS AI Labs working on recommender systems. His research interests lie in active learning, generative models, time series analysis, and online decision-making. Outside of work, he is an aviation enthusiast.
Hao Ding is a Senior Applied Scientist at AWS AI Labs and is working on advancing the recommender system for Amazon Personalize. His research interests lie in recommendation foundation models, Bayesian deep learning, large language models, and their applications in recommendation.
Rishabh Agrawal is a Senior Software Engineer working on AI services at AWS. In his spare time, he enjoys hiking, traveling and reading.

Get started with Amazon Titan Text Embeddings V2: A new state-of-the-art embeddings model on Amazon Bedrock
Embeddings are integral to various natural language processing (NLP) applications, and their quality is crucial for optimal performance. They are commonly used in knowledge bases to represent textual data as dense vectors, enabling efficient similarity search and retrieval. In Retrieval Augmented Generation (RAG), embeddings are used to retrieve relevant passages from a corpus to provide context for language models to generate informed, knowledge-grounded responses. Embeddings also play a key role in personalization and recommendation systems by representing user preferences, item characteristics, and historical interactions as vectors, allowing calculation of similarities for personalized recommendations based on user behavior and item embeddings. As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
In September of 2023, we announced the launch of Amazon Titan Text Embeddings V1, a multilingual text embeddings model that converts text inputs like single words, phrases, or large documents into high-dimensional numerical vector representations. Since then, many of our customers have used the V1 model, which supported over 25 languages, with an input up to 8,192 tokens and outputs vector of 1,536 dimensions for high accuracy and low latency. The model was made available as a serverless offering via Amazon Bedrock, simplifying embedding generation and integration with downstream applications. We published a follow-up post on January 31, 2024, and provided code examples using AWS SDKs and LangChain, showcasing a Streamlit semantic search app.
Today, we are happy to announce Amazon Titan Text Embeddings V2, our second-generation embeddings model for Amazon Bedrock. The new model is optimized for the most common use cases we see with many of our active customers, including RAG, multi-language, and code embedding use cases. The following table summarizes the key differences compared to V1.
Feature
Amazon Titan Text Embeddings V1
Amazon Titan Text Embeddings V2
Output dimension support
1536
256, 512, 1024
Language support
25+
100+
Unit vector normalization support
No
Yes
Price per million tokens
$0.10
$0.02 per 1 million tokens, or $0.00002 per 1,000 tokens
With these new features, we expect many more customers choosing Amazon Titan Text Embeddings V2 to build common generative artificial intelligence (AI) applications. In this post, we discuss the benefits of the V2 model, how to conduct your own evaluation of the model, and how to migrate to using the new model.
Let’s dig in!
Benefits of Amazon Titan Text Embeddings V2
Amazon Titan Text Embeddings V2 is the second-generation embedding model for Amazon Bedrock, optimized for some of the most common customer use cases we have seen with our customers. Some of the key features include:
Optimized for RAG solutions
Flexible embedding sizes
Improved multilingual support and code
Embeddings have become an integral part of various NLP applications, and their quality is crucial for achieving optimal performance.
The large language model (LLM) landscape is rapidly evolving, with leading providers offering increasingly powerful and versatile embedding models. Although incremental improvements in embedding quality may seem modest at the high level, the actual benefits can be significant for specific use cases. For example, in a recommendation system for a large ecommerce platform, a modest increase in recommendation accuracy could translate into significant additional revenue.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets. MTEB encompasses 8 different embedding tasks, covering a total of 58 datasets and 112 languages. In this benchmark, 33 different text embedding models were evaluated on the MTEB tasks. A key finding from the benchmark was that no single text embedding method emerged as the clear leader across all tasks and datasets. Each model exhibited strengths and weaknesses depending on the specific embedding task and data characteristics. This highlights the need for continued research into developing more versatile and robust text embedding techniques that can perform well across diverse use cases and language domains.
Although this is a useful benchmark, we caution our enterprise customers with the following considerations:
Although the MTEB leaderboard is widely recognized, it provides only a partial assessment by focusing solely on accuracy metrics and overlooking crucial practical factors like inference latency and model capabilities. The leaderboard rankings combine and compare embedding models across different vector dimensions, making direct and fair model comparisons challenging.
Additionally, the leaders on this accuracy-centric leaderboard change frequently as new models are continually introduced, providing a shifting and incomplete perspective on practical model performance trade-offs that real-world applications must consider beyond just accuracy numbers.
Lastly, costs need to be weighed against the expected benefits and performance improvements in the specific use case. A small gain in accuracy may not justify the significant overhead and opportunity costs of transitioning embeddings models, especially in large-scale, business-critical applications. Enterprises should perform a rigorous cost-benefit analysis to make sure the projected performance uplift from an updated embeddings model provides sufficient return on investment (ROI) to offset the migration costs and operational disruption.
In summary, start with evaluating the benchmark scores, but don’t decide until you have done your own due diligence.
Benchmark results
The Amazon Titan Text Embeddings V2 model has the ability to output embeddings of various size. This implies that if you use a lower size, you’ll reduce your memory footprint, which will translate directly into cost savings. The default size is 1024, compared to V1, which is an 1536 output size, implying a direct cost reduction of approximately 33%, which translates into savings given the cost of a RAG solution has a major component in the form of a vector databases. In our internal testing, we found that using the 256-output token resulted in only about 3.24% accuracy loss while translating to a four times saving due to size reduction. Running our evaluation on MTEB datasets, we found Amazon Titan Text Embeddings V2 to perform competitively with scores like 57.5 on reranking tasks, for example. With the model trained on over 100 languages, it’s no surprise the model achieves scores like 55 on the MIRACL multilingual dataset and has an overall weighted average MTEB score of 60.37. Full MTEB scores are available on the MTEB leaderboard.
However, we strongly encourage you to run your own benchmarks with your own dataset to understand the operational metrics. A sample notebook showing how to run the benchmarks against the MTEB datasets is hosted here. The key steps involved are:
Choose a representative set of data to embed and keywords to search.
Use the Amazon Titan Text Embeddings V2 model to embed your data and keywords, adjusting the chunk size and overlap as needed.
Carry out a similarity search using your preferred vector comparison method (such as Euclidean distance or cosine similarity).
Use Amazon Titan Text Embeddings V2 on Amazon Bedrock
The new Amazon Titan Text Embeddings V2 model is available through the fully managed, serverless experience on Amazon Bedrock. You can use the model through either the Amazon Bedrock REST API or the AWS SDK. The required parameters are the text that you want to generate the embeddings of and the modelID parameter, which represents the name of the Amazon Titan Text Embeddings model. Furthermore, now you can specify the output size of the vector, which is a significant feature of the V2 model.
Throughput has been a key requirement for running large ingestion workloads, and the Amazon Titan Text Embeddings model supports batching via Bedrock Batch to increase the throughput for your workloads. The following code is an example using the AWS SDK for Python (Boto3):
The full notebook is available at on the Github Repo.
With Amazon Titan Text Embeddings, you can input up to 8,192 tokens, allowing you to work with phrases or entire documents based on your use case. The model returns output vectors of a range of dimensions from 256–1024 without sacrificing accuracy, while also optimizing for cost storage and low latency. Typically, you will find larger content window models tuned for accuracy while sacrificing latency because they’re typically used in asynchronous workloads. However, with its larger content window, Amazon Titan Text Embeddings is able to achieve low latency, and with batching, it gives higher throughput for your workloads.
Run your own benchmarking
We always encourage our customers to perform their own benchmarking using their documents or the standard MTEB datasets and evaluation. For a sample of how to use the MTEB, see the GitHub repo. This notebook shows you how to load the dataset and set up evaluation for your specific use case (task) and run the benchmarking. If you run the benchmarking with your dataset, the typical steps involved are:
Use the Amazon Titan Text Embeddings V2 model to embed your data and keywords, adjusting the chunk size and overlap as needed.
Run similarity searches using your preferred distance metrics based on your choice of vector database.
A sample notebook showing how to use an in-memory database is available in the GitHub repo. This is a sample setup and should not be used for your production workloads where you would be connecting to robust vector database offerings like Amazon OpenSearch Serverless.
Migrate to Amazon Titan Text Embeddings V2
The cost and performance advantages provided by the V2 model are compelling reasons to consider reindexing your existing vector embeddings using V2. Let’s explore a few examples to illustrate the potential benefits, focusing solely on embedding costs.
Use case 1: High volume of searches
This first use case pertains to customers with a high volume of searches. The details are as follows:
Scenario:
1 million documents, 100 million chunks, 1,000 average tokens per chunk
100,000 searches per day, 1,000 token size for search
One-time cost:
Number of tokens: 100,000 million
Price per million tokens: $0.02
Reindexing cost: 100,000 * $0.02 = $2,000
Ongoing monthly savings (compared to V1):
Tokens embedded per month: 30 * 100,000 * 1,000 = 3,000 million
Savings per month (when migrating from V1 to V2): 3,000 * ($0.1 – $0.02) = $240
For this use case, the one-time reindexing cost of $2,000 will likely break even within 8–9 months through the ongoing monthly savings.
Use case 2: Ongoing indexing
This use case is for customers with ongoing indexing. The details are as follows:
Scenario:
500,000 documents, 50 million chunks, average 1,000 tokens per chunk
10,000 (2%) new documents added per month
1,000 searches per day, 1,000 token size for search
One-time cost:
Number of tokens: 50,000 million
Price per million tokens: $0.02
Reindexing cost: 50,000 * $0.02 = $1,000
Ongoing monthly savings (compared to V1):
Tokens embedded per month for storage: 1,000 * 1,000 * 1,000 = 1,000 million
Tokens embedded per month for search: 30 * 1,000 * 1,000 = 30 million
Savings per month (vs. V1): 1,030 * ($0.1 – $0.02) = $82.4
For this use case, the one-time reindexing cost of $1,000 nets an estimated monthly savings of $82.4.
These calculations do not account for the additional savings due to the reduced storage size (up to four times) with V2. This could translate into further cost savings in terms of your vector database storage requirements. The extent of these savings will vary depending on your specific data storage needs.
Conclusion
In this post, we introduced the new Amazon Titan Text Embeddings V2 model, with superior performance across various use cases like retrieval, reranking, and multilingual tasks. You can potentially realize substantial cost savings and performance improvements by reindexing your vector embeddings using the V2 model. The specific benefits will vary based on factors such as the volume of data, search traffic, and storage requirements, but the examples discussed in this post illustrate the potential value proposition. Amazon Titan Text Embeddings V2 is available today in the us-east-1 and us-west-2 AWS Regions.
About the authors
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Pradeep Sridharan is a Senior Solutions Architect at AWS. He has years of experience in digital business transformation—designing and implementing solutions to drive market competitiveness and revenue growth across multiple sectors. He specializes in AI/ML, Data Analytics and Application Modernization and Migration. Pradeep is based in Arizona (US).
Anuradha Durfee is a Senior Product Manager at AWS working on generative AI. She has spent the last five years working on natural language understanding and is motivated by enabling life-like conversations between humans and technology. Anuradha is based in Boston, MA.

The Science of Perception & How we Hallucinate our Own Reality
Originally Published on Stefan Speaks
Continue reading on Becoming Human: Artificial Intelligence Magazine »
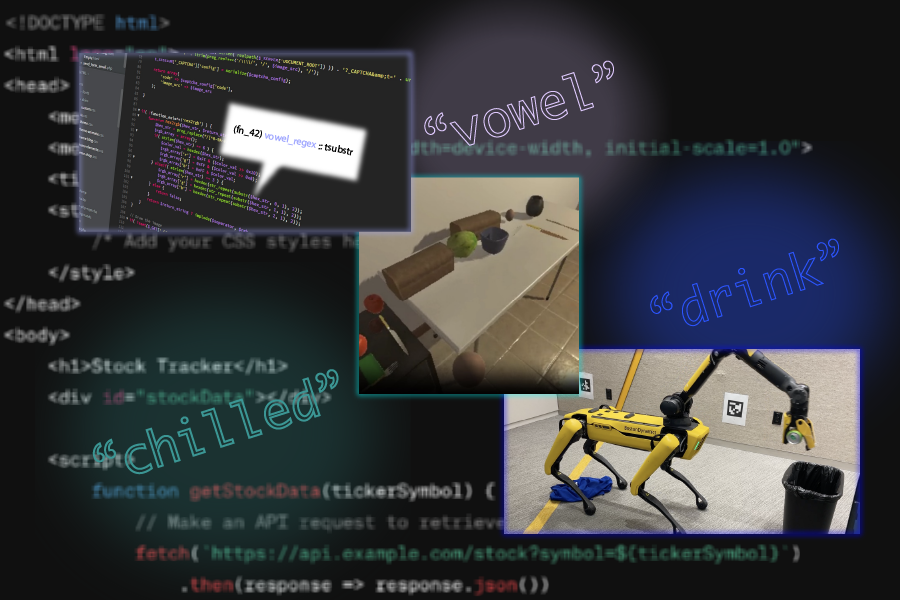
Natural language boosts LLM performance in coding, planning, and robotics
Large language models (LLMs) are becoming increasingly useful for programming and robotics tasks, but for more complicated reasoning problems, the gap between these systems and humans looms large. Without the ability to learn new concepts like humans do, these systems fail to form good abstractions — essentially, high-level representations of complex concepts that skip less-important details — and thus sputter when asked to do more sophisticated tasks.
Luckily, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have found a treasure trove of abstractions within natural language. In three papers to be presented at the International Conference on Learning Representations this month, the group shows how our everyday words are a rich source of context for language models, helping them build better overarching representations for code synthesis, AI planning, and robotic navigation and manipulation.
The three separate frameworks build libraries of abstractions for their given task: LILO (library induction from language observations) can synthesize, compress, and document code; Ada (action domain acquisition) explores sequential decision-making for artificial intelligence agents; and LGA (language-guided abstraction) helps robots better understand their environments to develop more feasible plans. Each system is a neurosymbolic method, a type of AI that blends human-like neural networks and program-like logical components.
LILO: A neurosymbolic framework that codes
Large language models can be used to quickly write solutions to small-scale coding tasks, but cannot yet architect entire software libraries like the ones written by human software engineers. To take their software development capabilities further, AI models need to refactor (cut down and combine) code into libraries of succinct, readable, and reusable programs.
Refactoring tools like the previously developed MIT-led Stitch algorithm can automatically identify abstractions, so, in a nod to the Disney movie “Lilo & Stitch,” CSAIL researchers combined these algorithmic refactoring approaches with LLMs. Their neurosymbolic method LILO uses a standard LLM to write code, then pairs it with Stitch to find abstractions that are comprehensively documented in a library.
LILO’s unique emphasis on natural language allows the system to do tasks that require human-like commonsense knowledge, such as identifying and removing all vowels from a string of code and drawing a snowflake. In both cases, the CSAIL system outperformed standalone LLMs, as well as a previous library learning algorithm from MIT called DreamCoder, indicating its ability to build a deeper understanding of the words within prompts. These encouraging results point to how LILO could assist with things like writing programs to manipulate documents like Excel spreadsheets, helping AI answer questions about visuals, and drawing 2D graphics.
“Language models prefer to work with functions that are named in natural language,” says Gabe Grand SM ’23, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead author on the research. “Our work creates more straightforward abstractions for language models and assigns natural language names and documentation to each one, leading to more interpretable code for programmers and improved system performance.”
When prompted on a programming task, LILO first uses an LLM to quickly propose solutions based on data it was trained on, and then the system slowly searches more exhaustively for outside solutions. Next, Stitch efficiently identifies common structures within the code and pulls out useful abstractions. These are then automatically named and documented by LILO, resulting in simplified programs that can be used by the system to solve more complex tasks.
The MIT framework writes programs in domain-specific programming languages, like Logo, a language developed at MIT in the 1970s to teach children about programming. Scaling up automated refactoring algorithms to handle more general programming languages like Python will be a focus for future research. Still, their work represents a step forward for how language models can facilitate increasingly elaborate coding activities.
Ada: Natural language guides AI task planning
Just like in programming, AI models that automate multi-step tasks in households and command-based video games lack abstractions. Imagine you’re cooking breakfast and ask your roommate to bring a hot egg to the table — they’ll intuitively abstract their background knowledge about cooking in your kitchen into a sequence of actions. In contrast, an LLM trained on similar information will still struggle to reason about what they need to build a flexible plan.
Named after the famed mathematician Ada Lovelace, who many consider the world’s first programmer, the CSAIL-led “Ada” framework makes headway on this issue by developing libraries of useful plans for virtual kitchen chores and gaming. The method trains on potential tasks and their natural language descriptions, then a language model proposes action abstractions from this dataset. A human operator scores and filters the best plans into a library, so that the best possible actions can be implemented into hierarchical plans for different tasks.
“Traditionally, large language models have struggled with more complex tasks because of problems like reasoning about abstractions,” says Ada lead researcher Lio Wong, an MIT graduate student in brain and cognitive sciences, CSAIL affiliate, and LILO coauthor. “But we can combine the tools that software engineers and roboticists use with LLMs to solve hard problems, such as decision-making in virtual environments.”
When the researchers incorporated the widely-used large language model GPT-4 into Ada, the system completed more tasks in a kitchen simulator and Mini Minecraft than the AI decision-making baseline “Code as Policies.” Ada used the background information hidden within natural language to understand how to place chilled wine in a cabinet and craft a bed. The results indicated a staggering 59 and 89 percent task accuracy improvement, respectively.
With this success, the researchers hope to generalize their work to real-world homes, with the hopes that Ada could assist with other household tasks and aid multiple robots in a kitchen. For now, its key limitation is that it uses a generic LLM, so the CSAIL team wants to apply a more powerful, fine-tuned language model that could assist with more extensive planning. Wong and her colleagues are also considering combining Ada with a robotic manipulation framework fresh out of CSAIL: LGA (language-guided abstraction).
Language-guided abstraction: Representations for robotic tasks
Andi Peng SM ’23, an MIT graduate student in electrical engineering and computer science and CSAIL affiliate, and her coauthors designed a method to help machines interpret their surroundings more like humans, cutting out unnecessary details in a complex environment like a factory or kitchen. Just like LILO and Ada, LGA has a novel focus on how natural language leads us to those better abstractions.
In these more unstructured environments, a robot will need some common sense about what it’s tasked with, even with basic training beforehand. Ask a robot to hand you a bowl, for instance, and the machine will need a general understanding of which features are important within its surroundings. From there, it can reason about how to give you the item you want.
In LGA’s case, humans first provide a pre-trained language model with a general task description using natural language, like “bring me my hat.” Then, the model translates this information into abstractions about the essential elements needed to perform this task. Finally, an imitation policy trained on a few demonstrations can implement these abstractions to guide a robot to grab the desired item.
Previous work required a person to take extensive notes on different manipulation tasks to pre-train a robot, which can be expensive. Remarkably, LGA guides language models to produce abstractions similar to those of a human annotator, but in less time. To illustrate this, LGA developed robotic policies to help Boston Dynamics’ Spot quadruped pick up fruits and throw drinks in a recycling bin. These experiments show how the MIT-developed method can scan the world and develop effective plans in unstructured environments, potentially guiding autonomous vehicles on the road and robots working in factories and kitchens.
“In robotics, a truth we often disregard is how much we need to refine our data to make a robot useful in the real world,” says Peng. “Beyond simply memorizing what’s in an image for training robots to perform tasks, we wanted to leverage computer vision and captioning models in conjunction with language. By producing text captions from what a robot sees, we show that language models can essentially build important world knowledge for a robot.”
The challenge for LGA is that some behaviors can’t be explained in language, making certain tasks underspecified. To expand how they represent features in an environment, Peng and her colleagues are considering incorporating multimodal visualization interfaces into their work. In the meantime, LGA provides a way for robots to gain a better feel for their surroundings when giving humans a helping hand.
An “exciting frontier” in AI
“Library learning represents one of the most exciting frontiers in artificial intelligence, offering a path towards discovering and reasoning over compositional abstractions,” says assistant professor at the University of Wisconsin-Madison Robert Hawkins, who was not involved with the papers. Hawkins notes that previous techniques exploring this subject have been “too computationally expensive to use at scale” and have an issue with the lambdas, or keywords used to describe new functions in many languages, that they generate. “They tend to produce opaque ‘lambda salads,’ big piles of hard-to-interpret functions. These recent papers demonstrate a compelling way forward by placing large language models in an interactive loop with symbolic search, compression, and planning algorithms. This work enables the rapid acquisition of more interpretable and adaptive libraries for the task at hand.”
By building libraries of high-quality code abstractions using natural language, the three neurosymbolic methods make it easier for language models to tackle more elaborate problems and environments in the future. This deeper understanding of the precise keywords within a prompt presents a path forward in developing more human-like AI models.
MIT CSAIL members are senior authors for each paper: Joshua Tenenbaum, a professor of brain and cognitive sciences, for both LILO and Ada; Julie Shah, head of the Department of Aeronautics and Astronautics, for LGA; and Jacob Andreas, associate professor of electrical engineering and computer science, for all three. The additional MIT authors are all PhD students: Maddy Bowers and Theo X. Olausson for LILO, Jiayuan Mao and Pratyusha Sharma for Ada, and Belinda Z. Li for LGA. Muxin Liu of Harvey Mudd College was a coauthor on LILO; Zachary Siegel of Princeton University, Jaihai Feng of the University of California at Berkeley, and Noa Korneev of Microsoft were coauthors on Ada; and Ilia Sucholutsky, Theodore R. Sumers, and Thomas L. Griffiths of Princeton were coauthors on LGA.
LILO and Ada were supported, in part, by MIT Quest for Intelligence, the MIT-IBM Watson AI Lab, Intel, U.S. Air Force Office of Scientific Research, the U.S. Defense Advanced Research Projects Agency, and the U.S. Office of Naval Research, with the latter project also receiving funding from the Center for Brains, Minds and Machines. LGA received funding from the U.S. National Science Foundation, Open Philanthropy, the Natural Sciences and Engineering Research Council of Canada, and the U.S. Department of Defense.

Simple guide to training Llama 2 with AWS Trainium on Amazon SageMaker
Large language models (LLMs) are making a significant impact in the realm of artificial intelligence (AI). Their impressive generative abilities have led to widespread adoption across various sectors and use cases, including content generation, sentiment analysis, chatbot development, and virtual assistant technology. Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. It comes in a range of parameter sizes—7 billion, 13 billion, and 70 billion—as well as pre-trained and fine-tuned variations. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart.
Many practitioners fine-tune or pre-train these Llama 2 models with their own text data to improve accuracy for their specific use case. However, in some cases, a challenge arises for practitioners: the high cost of fine-tuning and training. As organizations strive to push the boundaries of what LLMs can achieve, the demand for cost-effective training solutions has never been more pressing. In this post, we explore how you can use the Neuron distributed training library to fine-tune, continuously pre-train, and reduce the cost of training LLMs such as Llama 2 with AWS Trainium instances on Amazon SageMaker.
AWS Trainium instances for training workloads
SageMaker ml.trn1 and ml.trn1n instances, powered by Trainium accelerators, are purpose-built for high-performance deep learning training and offer up to 50% cost-to-train savings over comparable training optimized Amazon Elastic Compute Cloud (Amazon EC2) instances. This post implements a solution with the ml.trn1.32xlarge Trainium instance type, typically used for training large-scale models. However, there are also comparable ml.trn1n instances that offer twice as much networking throughput (1,600 Gbps) via Amazon Elastic Fabric Adapter (EFAv2). SageMaker Training supports the availability of ml.trn1 and ml.trn1n instances in the US East (N. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region. These instances are available in the listed Regions with On-Demand, Reserved, and Spot Instances, or additionally as part of a Savings Plan.
For more information on Trainium Accelerator chips, refer to Achieve high performance with lowest cost for generative AI inference using AWS Inferentia2 and AWS Trainium on Amazon SageMaker. Additionally, check out AWS Trainium Customers to learn more about customer testimonials, or see Amazon EC2 Trn1 Instances for High-Performance Model Training are Now Available to dive into the accelerator highlights and specifications.
Using the Neuron Distributed library with SageMaker
SageMaker is a fully managed service that provides developers, data scientists, and practitioners the ability to build, train, and deploy machine learning (ML) models at scale. SageMaker Training includes features that improve and simplify the ML training experience, including managed infrastructure and images for deep learning, automatic model tuning with hyperparameter optimization, and a pay-for-what-you-use billing structure. This section highlights the advantages of using SageMaker for distributed training with the Neuron Distributed library—specifically, the managed infrastructure, time-to-train, and cost-to-train benefits of its associated resiliency and recovery features, and is part of the AWS Neuron SDK used to run deep learning workloads on AWS Inferentia and AWS Trainum based instances.
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. Although hardware failures while training on a single instance may be rare, issues resulting in stalled training become more prevalent as a cluster grows to tens or hundreds of instances. Regular checkpointing helps mitigate wasted compute time, but engineering teams managing their own infrastructure must still closely monitor their workloads and be prepared to remediate a failure at all hours to minimize training downtime. The managed infrastructure of SageMaker Training includes several resiliency features that make this monitoring and recovery process streamlined:
Cluster health checks – Before a training job starts, SageMaker runs health checks and verifies communication on the provisioned instances. It then replaces any faulty instances, if necessary, to make sure the training script starts running on a healthy cluster of instances. Health checks are currently enabled for the TRN1 instance family as well as P* and G* GPU-based instance types.
Automatic checkpointing – Checkpoints from a local path (/opt/ml/checkpoints by default) are automatically copied to an Amazon Simple Storage Service (Amazon S3) location specified by the user. When training is restarted, SageMaker automatically copies the previously saved checkpoints from the S3 location back to the local checkpoint directory to make sure the training script can load and resume the last saved checkpoint.
Monitoring and tracking training – In the case of a node failure, it’s important to have the visibility of where the failure occurs. Using PyTorch Neuron gives data scientists the ability to track training progress in a TensorBoard. This allows you to capture the loss of the training job to determine when the training job should be stopped to identify the convergence of the model for optimal training.
Built-in retries and cluster repair – You can configure SageMaker to automatically retry training jobs that fail with a SageMaker internal server error (ISE). As part of retrying a job, SageMaker replaces any instances that encountered unrecoverable errors with fresh instances, reboots all healthy instances, and starts the job again. This results in faster restarts and workload completion. Cluster update is currently enabled for the TRN1 instance family as well as P and G GPU-based instance types. Practitioners can add in their own applicative retry mechanism around the client code that submits the job, to handle other types of launch errors, such as like exceeding your account quota.
For customers working with large clusters of hundreds of instances for a training job, the resiliency and recovery features of SageMaker Training can reduce total time for a model to converge by up to 20% via fewer failures and faster recovery. This also enables engineering teams to monitor and react to failures at all hours. Although SageMaker training jobs are suitable for general-purpose training use cases with customizable configurations and integration with the broader AWS ecosystem, Amazon SageMaker HyperPod is specifically optimized for efficient and resilient training of foundation models at scale. For more information on SageMaker HyperPod use cases, refer to the SageMaker HyperPod developer guide.
In this post, we use the Neuron Distributed library to continuously pre-train a Llama 2 model using tensor and pipeline parallelism using SageMaker training jobs. To learn more about the resiliency and recovery features of SageMaker Training, refer to Training large language models on Amazon SageMaker: Best practices.
Solution overview
In this solution, we use an ml.t3.medium instance type on a SageMaker Jupyter notebook to process the provided cells. We will be continuously pre-training our llama2-70b model using the trn1.32xlarge Trainium instance. First, let’s familiarize ourselves with the techniques we use to handle the distribution of the training job created in our solution to contiuously pre-train our llama2-70b model using the Neuron distributed training library.
The techniques used to convert the pre-trained weights in the convert_pretrained_weights.ipynb notebook into a .pt (PyTorch) weights file are called pipeline parallelism and tensor parallelism:
Pipeline parallelism involves a training strategy that combines elements of pipeline parallelism to optimize the training process by splitting a batch or deep neural network into multiple microbatches or layers, allowing each stage worker to process one microbatch.
Tensor parallelism splits tensors of a neural network into multiple devices. This technique allows models with large tensors that can’t fit into the memory of a single device.
After we convert our pre-trained weights with the preceding techniques in our first notebook, we follow two separate notebooks in the same sagemaker-trainium-examples folder. The second notebook is Training_llama2_70b.ipynb, which walks through the continuous pre-training process by saving our checkpoint of converted model weights in the first notebook and prepping it for inference. When this step is complete, we can run the Convert_Nxd_to_hf.ipynb notebook, which takes our pre-trained weights using the NeuronX library and converts it into a readable format in Hugging Face to serve inference.
Prerequisites
You need to complete some prerequisites before you can run the first notebook.
First, make sure you have created a Hugging Face access token so you can download the Hugging Face tokenizer to be used later. After you have the access token, you need to make a few quota increase requests for SageMaker. You need to request a minimum of 8 Trn1 instances ranging to a maximum of 32 Trn1 instances (depending on time-to-train and cost-to-train trade-offs for your use case).
On the Service Quotas console, request the following SageMaker quotas:
Trainium instances (ml.trn1.32xlarge) for training job usage: 8–32
ml.trn1.32xlarge for training warm pool usage: 8–32
Maximum number of instances per training job: 8–32
It may take up to 24 hours for the quota increase to get approved. However, after submitting the quota increase, you can go to the sagemaker-trainium-examples GitHub repo and locate the convert_pretrained_weights.ipynb file. This is the file that you use to begin the continual pre-training process.
Now that you’re ready to begin the process to continuously pre-train the llama2-70b model, you can convert the pre-trained weights in the next section to prep the model and create the checkpoint.
Getting started
Complete the following steps:
Install all the required packages and libraries: SageMaker, Boto3, transformers, and datasets.
These packages make sure that you can set up your environment to access your pre-trained Llama 2 model, download your tokenizer, and get your pre-training dataset.
After the packages are installed, retrieve your Hugging Face access token, and download and define your tokenizer.
The tokenizer meta-llama/Llama-2-70b-hf is a specialized tokenizer that breaks down text into smaller units for natural language processing. This tokenized data will later be uploaded into Amazon S3 to allow for running your training job.
After following the above cells, you will now download the wikicorpus dataset from the Hugging Face dataset.
Tokenize the dataset with the llama-2 tokenizer that you just initialized.
By tokenizing the data, you’re preparing to pre-train your Llama 2 model to enhance the model’s performance to expose it to the trilingual (Catalan, English, Spanish) text data in the wikicorpus dataset to learn intricate patterns and relationships in the dataset.
After the data is tokenized, run the following cell to store the training dataset to s3:
The cell above makes sure that you define the training_input_path and have uploaded the data to your S3 bucket. You’re now ready to begin the training job process.
Run the training job
For the training job, we use the trn1.32xlarge instances with each of the instances having 32 neuron cores. We use tensor parallelism and pipeline parallelism, which allows you to shard the model across Neuron cores for training.
The following code is the configuration for pretraining llama2-70b with trn1:
Now you can define the hyperparameters for training. Note that adjusting these parameters based on hardware capabilities, dataset characteristics, and convergence requirements can significantly impact training performance and efficiency.
The following is the code for the hyperparameters:
Now you specify the Docker image that will be used to train the model on Trainium:
The image we defined is designed for PyTorch training with Neuron optimizations. This image is configured to work with PyTorch, using Neuron SDK version 2.18.0 for enhanced performance and efficiency on Trn1 instances equipped with AWS Trainium chips. This image is also compatible with Python 3.10, indicated by the py310, and is based on Ubuntu 20.04.
Prior to starting your training job, you need to configure it by defining all necessary variables. You do so by defining the training job name, checkpoint directory, and cache directory:
The parameters enable you to do the following:
The training job allows you to identify and track individual training jobs based on timestamps
The checkpoint directory specifies the S3 URI where the checkpoint data, weights, and other information are stored for the trained model
The cache directory helps optimize the training process by storing and reusing previously calculated values, from the checkpoint directory, reducing redundancy and improving efficiency
The environment variables make sure that the training job is optimally configured and settings are tailored to enable efficient and effective training using features like RDMA, optimized memory allocation, fused operations, and Neuron-specific device optimizations
After you have defined your training job and configured all directories and environment variables for an optimal training pipeline, you now set up your PyTorch estimator to begin the training job on SageMaker. A SageMaker estimator is a high-level interface that handles the end-to-end SageMaker training and deployment tasks.
The entry_point is specified as the Python script run_llama_nxd.py. We use the instance_type ml.trn1.32xlarge, the instance count is 32 (which was previously defined as a global variable in the configuration code), and input_mode is set to FastFile. Fast File mode in SageMaker streams data from Amazon S3 on demand, which optimizes data loading performance by fetching data as needed, reducing overall resource consumption. For more information on input, refer to Access Training Data.
Finally, you can start the training job with the SageMaker fit() method, which trains the model based on the defined hyperparameters:
You have successfully started the process to continuously pre-train a llama2-70b model by converting pre-trained weights with tokenized data using SageMaker training on Trainium instances.
Continuous pre-training
After following the prerequisites, completing the provided notebook, and converting the pre-trained weights as a checkpoint, you can now begin the continual pre-training process, using the checkpoint as a point of reference to pre-train the llama2-70b model. The techniques used to convert the pre-trained weights in the convert_pretrained_weights.ipynb notebook into a .pt (PyTorch) weights file are called pipeline parallelism and tensor parallelism.
To begin the continuous pre-training process, follow the Training_llama2_70b.ipynb file in the sagemaker-trainium-examples repo.
Given the large size of the llama2-70b model, you need to convert the pre-trained weights into a more efficient and useable format (.pt). You can do so by defining the hyperparameters in your configuration to store converted weights and checkpoints. The following are the hyperparameters:
If you look at the hyperparameters, the output_dir is used as a reference for pre-training. If you are at this cell, you should have already followed the Training_llama2_70b.ipynb notebook and gone through the process of setting up your SageMaker client and Docker image, and preparing the pre-trained weights for pre-training. You’re now ready to perform the continuous pre-training process on the llama2-70b model.
We use the following parameters to take the pre-trained weights stored in output_dir in the convert_pretrained_weights.ipynb file to be reused continuously for pre-training:
After these hyperparameters are implemented, you can run the rest of the notebook cells to complete the continuous pre-training process. After the SageMaker estimator has completed the training job, you can locate the new checkpoint in the S3 checkpoint directory containing the weights. You can now locate the convert_Nxd_to_hf.ipynb file to get the checkpoint ready for inferencing.
Convert the Neuron Distributed checkpoint for inferencing
Checkpoints play a vital role in the context of distributed training with the NeuronX library because it has checkpoint compatibility with Hugging Face Transformers. You can get the training job output ready for inferencing by taking the training job that is saved as a NeuronX distributed checkpoint and converting the weights into .pt weights files.
To convert the checkpoints to Hugging Face format using NeuronX, you first need to save the S3 nxd_checkpoint_path directory:
After you save the checkpoint in the nxd_checkpoint_path directory, you can save your hyperparameters and configure your SageMaker estimator, which makes sure the pre-training process can begin. You can now run the fit() function within the estimator to convert the pre-trained weights into a checkpoint for inferencing with the following cell:
Summary
You have successfully performed continuous pre-training on a llama2-70b model by converting your pre-trained weights and checkpoint to be used to serve inference using the Neuron SDK and Trainium instances. By following the solution in this post, you should now know how to configure a pipeline for continuous pre-training of an LLM using SageMaker and Trainium accelerator chips.
For more information on how to use Trainium for your workloads, refer to the Neuron SDK documentation or reach out directly to the team. We value customer feedback and are always looking to engage with ML practitioners and builders. Feel free to leave comments or questions in the comments section.
About the authors
Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions and conducting research to help customers hyperscale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers & acquisitions. Marco is based in Seattle, WA and enjoys writing, reading, exercising, and building applications in his free time.
Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and Data Analytics. At AWS, Armando helps customers integrating cutting-edge generative AI capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, train, and migrate ML production workloads to SageMaker at scale. He specializes in deep learning, especially in the area of NLP and CV. Outside of work, he enjoys running and hiking.
Robert Van Dusen is a Senior Product Manager with Amazon SageMaker. He leads frameworks, compilers, and optimization techniques for deep learning training.
Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
Rohit Talluri is a Generative AI GTM Specialist (Tech BD) at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies with a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife.
Machine listening: Making speech recognition systems more inclusive
One group commonly misunderstood by voice technology are individuals who speak African American English, or AAE. Researchers designed an experiment to test how AAE speakers adapt their speech when imagining talking to a voice assistant, compared to talking to a friend, family member, or stranger. The study tested familiar human, unfamiliar human, and voice assistant-directed speech conditions by comparing speech rate and pitch variation. Analysis of the recordings showed that the speakers exhibited two consistent adjustments when they were talking to voice technology compared to talking to another person: a slower rate of speech with less pitch variation.

Fine-tune and deploy language models with Amazon SageMaker Canvas and Amazon Bedrock
Imagine harnessing the power of advanced language models to understand and respond to your customers’ inquiries. Amazon Bedrock, a fully managed service providing access to such models, makes this possible. Fine-tuning large language models (LLMs) on domain-specific data supercharges tasks like answering product questions or generating relevant content.
In this post, we show how Amazon Bedrock and Amazon SageMaker Canvas, a no-code AI suite, allow business users without deep technical expertise to fine-tune and deploy LLMs. You can transform customer interaction using datasets like product Q&As with just a few clicks using Amazon Bedrock and Amazon SageMaker JumpStart models.
Solution overview
The following diagram illustrates this architecture.
In the following sections, we show you how to fine-tune a model by preparing your dataset, creating a new model, importing the dataset, and selecting a foundation model. We also demonstrate how to analyze and test the model, and then deploy the model via Amazon Bedrock.
Prerequisites
First-time users need an AWS account and AWS Identity and Access Management (IAM) role with SageMaker, Amazon Bedrock, and Amazon Simple Storage Service (Amazon S3) access.
To follow along with this post, complete the prerequisite steps to create a domain and enable access to Amazon Bedrock models:
Create a SageMaker domain.
On the domain details page, view the user profiles.
Choose Launch by your profile, and choose Canvas.
Confirm that your SageMaker IAM role and domain roles have the necessary permissions and trust relationships.
On the Amazon Bedrock console, choose Model access in the navigation pane.
Choose Manage model access.
Select Amazon to enable the Amazon Titan model.
Prepare your dataset
Complete the following steps to prepare your dataset:
Download the following CSV dataset of question-answer pairs.
Confirm that your dataset is free from formatting issues.
Copy the data to a new sheet and delete the original.
Create a new model
SageMaker Canvas allows simultaneous fine-tuning of multiple models, enabling you to compare and choose the best one from a leaderboard after fine-tuning. However, this post focuses on the Amazon Titan Text G1-Express LLM. Complete the following steps to create your model:
In SageMaker canvas, choose My models in the navigation pane.
Choose New model.
For Model name, enter a name (for example, MyModel).
For Problem type¸ select Fine-tune foundation model.
Choose Create.
The next step is to import your dataset into SageMaker Canvas:
Create a dataset named QA-Pairs.
Upload the prepared CSV file or select it from an S3 bucket.
Choose the dataset, then choose Select dataset.
Select a foundation model
After you upload your dataset, select a foundation model and fine-tune it with your dataset. Complete the following steps:
On the Fine-tune tab, on the Select base models menu¸ select Titan Express.
For Select input column, choose question.
For Select output column, choose answer.
Choose Fine-tune.
Wait 2–5 hours for SageMaker to finish fine-tuning your models.
Analyze the model
When the fine-tuning is complete, you can view the stats about your new model, including:
Training loss – The penalty for each mistake in next-word prediction during training. Lower values indicate better performance.
Training perplexity – A measure of the model’s surprise when encountering text during training. Lower perplexity suggests higher model confidence.
Validation loss and validation perplexity – Similar to the training metrics, but measured during the validation stage.
To get a detailed report on your custom model’s performance across various dimensions, such as toxicity and accuracy, choose Generate evaluation report. Then select Download report.
Canvas offers a Python Jupyter notebook detailing your fine-tuning job, alleviating concerns about vendor lock-in associated with no-code tools and enabling detail sharing with data science teams for further validation and deployment.
If you selected multiple foundation models to create custom models from your dataset, check out the Model leaderboard to compare them on dimensions like loss and perplexity.
Test the models
You now have access to custom models that can be tested in SageMaker Canvas. Complete the following steps to test the models:
Choose Test in Ready-to-Use Models and wait 15–30 minutes for your test endpoint to be deployed.
This test endpoint will only stay up for 2 hours to avoid unintended costs.
When the deployment is complete, you’ll be redirected to the SageMaker Canvas playground, with your model pre-selected.
Choose Compare and select the foundation model used for your custom model.
Enter a phrase directly from your training dataset, to make sure the custom model at least does better at such a question.
For this example, we enter the question, “Who developed the lie-detecting algorithm Fraudoscope?”
The fine-tuned model responded correctly:
“The lie-detecting algorithm Fraudoscope was developed by Tselina Data Lab.”
Amazon Titan responded incorrectly and verbosely. However, to its credit, the model produced important ethical concerns and limitations of facial recognition technologies in general:
Let’s ask a question about an NVIDIA chip, which powers Amazon Elastic Compute Cloud (Amazon EC2) P4d instances: “How much memory in an A100?”
Again, the custom model not only gets the answer more correct, but it also answers with the brevity you would want from a question-answer bot:
“An A100 GPU provides up to 40 GB of high-speed HBM2 memory.”
The Amazon Titan answer is incorrect:
Deploy the model via Amazon Bedrock
For production use, especially if you’re considering providing access to dozens or even thousands of employees by embedding the model into an application, you can deploy the models as API endpoints. Complete the following steps to deploy your model:
On the Amazon Bedrock console, choose Foundation models in the navigation pane, then choose Custom models.
Locate the model with the prefix Canvas- with Amazon Titan as the source.
Alternatively, you can use the AWS Command Line Interface (AWS CLI): aws bedrock list-custom-models
Make note of the modelArn, which you’ll use in the next step, and the modelName, or save them directly as variables:
To start using your model, you must provision throughput.
On the Amazon Bedrock console, choose Purchase Provisioned Throughput.
Name it, set 1 model unit, no commitment term.
Confirm the purchase.
Alternatively, you can use the AWS CLI:
Or, if you saved the values as variables in the previous step, use the following code:
After about five minutes, the model status changes from Creating to InService.
If you’re using the AWS CLI, you can see the status via aws bedrock list-provisioned-model-throughputs.
Use the model
You can access your fine-tuned LLM through the Amazon Bedrock console, API, CLI, or SDKs.
In the Chat Playground, choose the category of fine-tuned models, select your Canvas- prefixed model, and the provisioned throughput.
Enrich your existing software as a service (SaaS), software platforms, web portals, or mobile apps with your fine-tuned LLM using the API or SDKs. These let you send prompts to the Amazon Bedrock endpoint using your preferred programming language.
The response demonstrates the model’s tailored ability to answer these types of questions:
“The lie-detecting algorithm Fraudoscope was developed by Tselina Data Lab.”
This improves the response from Amazon Titan before fine-tuning:
“Marston Morse developed the lie-detecting algorithm Fraudoscope.”
For a full example of invoking models on Amazon Bedrock, refer to the following GitHub repository. This repository provides a ready-to-use code base that lets you experiment with various LLMs and deploy a versatile chatbot architecture within your AWS account. You now have the skills to use this with your custom model.
Another repository that may spark your imagination is Amazon Bedrock Samples, which can help you get started on a number of other use cases.
Conclusion
In this post, we showed you how to fine-tune an LLM to better fit your business needs, deploy your custom model as an Amazon Bedrock API endpoint, and use that endpoint in application code. This unlocked the custom language model’s power to a broader set of people within your business.
Although we used examples based on a sample dataset, this post showcased these tools’ capabilities and potential applications in real-world scenarios. The process is straightforward and applicable to various datasets, such as your organization’s FAQs, provided they are in CSV format.
Take what you learned and start brainstorming ways to use custom AI models in your organization. For further inspiration, see Overcoming common contact center challenges with generative AI and Amazon SageMaker Canvas and AWS re:Invent 2023 – New LLM capabilities in Amazon SageMaker Canvas, with Bain & Company (AIM363).
About the Authors
Yann Stoneman is a Solutions Architect at AWS focused on machine learning and serverless application development. With a background in software engineering and a blend of arts and tech education from Juilliard and Columbia, Yann brings a creative approach to AI challenges. He actively shares his expertise through his YouTube channel, blog posts, and presentations.
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customer throughout Benelux. He has been a developer since very young, starting to code at the age of 7. He started learning AI/ML in his later years of university, and has fallen in love with it since then.

Improving inclusion and accessibility through automated document translation with an open source app using Amazon Translate
Organizations often offer support in multiple languages, saying “contact us for translations.” However, customers who don’t speak the predominant language often don’t know that translations are available or how to request them. This can lead to poor customer experience and lost business. A better approach is proactively providing information in multiple languages so customers can access it directly. This leads to more informed, satisfied, and included customers.
In this post, we share how we identified these challenges and overcame them through our work with Swindon Borough Council. We developed the Document Translation app, which uses Amazon Translate, to address these issues. The app is a business user app for self-serve translations. The app is created in partnership with Swindon Council and released as open source code freely available for your organization to use.
Translation challenges
We identified three key challenges:
Accuracy and quality
Cost to translate
Time to translate
Accuracy and quality
Translation accuracy and quality are critical, because the results must be accurate and understood. As quoted in the Swindon Borough Council case study:
“The council ran small-scale trials with the main digital translation providers that can support the different languages spoken by Swindon’s citizens. It recruited local bilingual volunteers to assess the quality of the machine translations against their first languages, and Amazon Translate came out on top.”
The Document Translation app uses Amazon Translate for performing translations. Amazon Translate provides high-quality document translations for contextual, accurate, and fluent translations. It supports many languages and dialects, providing broad coverage for customers worldwide. Custom terminology, a feature of Amazon Translate,is dynamically utilized by the app workflow when a language has matching custom terminology available.
Cost to translate
High costs of manual translation can prohibit organizations from supporting multiple languages, straining already tight budgets. Balancing language inclusivity and budget limitations poses a significant challenge when relying solely on traditional translation methods.
Swindon Borough Council paid around £159.81 ($194.32 USD) per single-page document, limiting them to providing translation only where legally required. As discussed in the case study, Swindon Borough Council slashed 99.96% of translation costs using Amazon Translate:
“Such dramatic savings mean that it’s no longer limited to translating only documents it is legally required to provide—it can offer citizens wider access to content for minimal extra cost.”
Customers report third-party translation services fees as a major cost. The neural machine translation technology of Amazon Translate dramatically lowers these costs.
Following the Cost Optimization pillar of the AWS Well-Architected Framework further led to implementing an AWS Graviton architecture using AWS Lambda and an infrequently accessed Amazon DynamoDB table class. With no server management overhead or continually running systems, this helps keep costs low.
Time to translate
Manual translation delays that lower customer satisfaction also include internal processes, approvals, and logistics arrangements in place to control costs and protect sensitive and private content. Swindon Borough Council stated that turnaround times could take up to 17 days:
“First, it was slow. The internal process required manual inputs from many different people. On average, that process took up to 12 days, and the time required by the translation agency was 3–5 days. That meant total translation time for a document was up to 17 days.”
This app offers a business user self-serve portal for document translations. Users can upload documents and download translations for sharing without slow manual intervention. Amazon Translate can perform translations in about 10 minutes.
Solution overview
The app’s business user portal is a browser-based UI that has been translated into all languages and dialects supported by Amazon Translate. The dynamic React UI doesn’t require server software. To accelerate development, UI components such as buttons and input boxes come from the AWS Cloudscape Design library. For interacting with AWS services, the AWS Amplify JS library for React simplifies the authentication, security, and API requests.
Fig.1 – Translating a document.
Fig.2 – Localized user interface.
Fig.3 – Client architecture overview.
The backend uses several serverless and event-driven AWS services, including AWS Step Functions for low-code workflows, AWS AppSync for a GraphQL API, and Amazon Translate. This architecture enables fast development and reduces ongoing management overhead, as shown in the following diagram.
Fig.4 – Translation architecture overview.
The app is built with Infrastructure as Code (IaC) using the AWS Cloud Development Kit (AWS CDK). The AWS CDK is an open source software development framework used to model and provision cloud applications. Using the Typescript CDK provides a reliable, repeatable, and extensible foundation for deployments. Paired with a consistent continuous integration and delivery (CI/CD) pipeline, deployments are predictable. Reusable components are extracted into constructs and imported where needed, providing consistency and best practices such as AWS Identity and Access Management (IAM) roles, Amazon CloudWatch logging, and AWS X-Ray tracing for all Lambda functions.
Fig.5 – Continuous integration and continuous delivery pipeline overview.
App deployment
The app is effortless to deploy using the AWS CDK. The AWS CDK allows modeling of the entire stack, including frontend React code, backend functions and workflows, and cloud infrastructure definitions packaged together.
Before deployment, review any prerequisites you may want to use, such as connecting this to your organization’s single sign-on with the SAML provider.
The installation wizard provides the necessary commands. AWS CloudShell allows you to run these commands without installing anything locally. The app documentation covers all advanced options available. Installation takes 30–60 minutes and is monitored from AWS CodePipeline.
Fig.6 – Installation wizard.
A self-paced Immersion Day is available for your technical teams to get hands-on experience with the services and build core components. Alternatively, your AWS account team can provide personalized guidance through the workshop.
Additional feature: Simply Readable
This app is designed with multiple features (as of this writing, Document Translation and Simply Readable). Simply Readable enables you to create Easy Read documents with generative artificial intelligence (AI) using Amazon Bedrock. The app can be installed with or without this feature.
Conclusion
The Document Translation app provides translations in your customers’ native languages. Amazon Translate enables accurate translation at scale. Communicating in customers’ languages shows respect, improves understanding, and builds trust.
Translation capabilities should be core to any growth strategy, building loyalty and revenue through superior localized experiences.
Business leaders should evaluate solutions like Amazon Translate to overcome language barriers and share their brand. Enabling multilingual communication conveys “We value you, we hear you, and we want your experience with us to be positive.”
To learn more about the app, see the FAQ.
About the Author
Philip Whiteside is a Solutions Architect (SA) at Amazon Web Services. Philip is passionate about overcoming barriers by utilizing technology.

Automate chatbot for document and data retrieval using Agents and Knowledge Bases for Amazon Bedrock
Numerous customers face challenges in managing diverse data sources and seek a chatbot solution capable of orchestrating these sources to offer comprehensive answers. This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. It allows you to retrieve data from sources beyond the foundation model, enhancing prompts by integrating contextually relevant retrieved data. You can use prompt engineering to prevent hallucination and make sure that the answer is grounded in the source documentations. To retrieve data from database, you can use foundation models (FMs) offered by Amazon Bedrock, converting text into SQL queries with specified constraints. This process empowers the extraction of data from Amazon Athena tables, effectively addressing inquiries related to data.
For handling more intricate queries, achieving comprehensive answers demands information sourced from both documentation and databases. Agents for Amazon Bedrock is a generative AI tool offered through Amazon Bedrock that enables generative AI applications to execute multistep tasks across company systems and data sources. This integration allows for the synthesis of combined information, resulting in detailed and exhaustive answers.
This post demonstrates how to build a chatbot using Amazon Bedrock including Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock, within an automated solution. The code used in this solution is available in the GitHub repo.
Solution overview
In this post, we use publicly available data, encompassing both unstructured and structured formats, to showcase our entirely automated chatbot system. Our unstructured data comes from the Amazon EC2 User Guide for Linux Instances and Amazon EC2 Instance Types documentation, and the structured data is derived from the EC2 Instance On-Demand Pricing for the US East (N. Virginia) AWS Region.
The following diagram illustrates the solution architecture.
The diagram details a comprehensive AWS Cloud-based setup within a specific Region, using multiple AWS services. The primary interface for the chatbot is a Streamlit application hosted on an Amazon Elastic Container Service (Amazon ECS) cluster, with accessibility managed by an Application Load Balancer. Queries made through this interface activate the AWS Lambda Invocation function, which interfaces with an agent. This agent responds to user inquiries by either consulting the knowledge base or by invoking an Agent Executor Lambda function. This function invokes a set of actions associated with the agent, following a predefined API schema. The knowledge base uses a serverless Amazon OpenSearch Service index as its vector database foundation. Additionally, the Agent Executor function generates SQL queries that are run against the AWS Glue database through Athena.
Deploy the solution with the AWS CDK
The AWS Cloud Development Kit (AWS CDK) is an open source software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. Our AWS CDK stack deploys resources from the following AWS services:
AWS Key Management Service (AWS KMS)
Application Load Balancer
Amazon Bedrock
Amazon Elastic Container Registry (Amazon ECR)
Amazon Elastic Container Service (Amazon ECS)
AWS Fargate
AWS Glue Data Catalog (for the AWS Glue database component)
AWS Identity and Access Management (IAM)
AWS Lambda
Amazon OpenSearch Service
Amazon Simple Storage Service (Amazon S3)
Amazon Virtual Private Cloud (Amazon VPC)
Refer to the instructions provided in the README.md file for deploying the solution using the AWS CDK. After you have completed all the necessary setup, you can deploy the stack with the following command:
Amazon Bedrock features
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In this section, we discuss some of the key Amazon Bedrock features and resources that we use in our solution.
Agents for Amazon Bedrock
Agents for Amazon Bedrock enables you to build and configure autonomous agents in your application. An agent helps your end-users complete actions based on organization data and user input. Agents orchestrate interactions between FMs, data sources, software applications, and user conversations.
For example, you can ask a question such as, “Which EC2 instance is recommended for machine learning model inference and how much does it cost?” The agent can help break down complex tasks into smaller tasks:
“To answer this question, I will:
1. Call the GET::ChatBotBedrockAgentActionGroup::getUc2Response function to get the latest EC2 instance type and pricing details for machine learning inference.
2. Call the GET::x_amz_knowledgebase_WSGY5QH4ZD::Search function to get recommendations on which EC2 instance type is best for machine learning inference.
3. Return the recommended EC2 instance type and the pricing details to the user.
I have checked that I have access to the GET::ChatBotBedrockAgentActionGroup::getUc2Response and GET::x_amz_knowledgebase_WSGY5QH4ZD::Search functions.”
Then the agent will gather information through these three steps and integrate them into a final answer:
“The AWS Inferentia and Trainium instances are well-suited for machine learning model inference workloads. The Inf1 and Trn1 instances deliver high performance inference using dedicated ML chips like Inferentia and Trainium at lower costs compared to GPU-based instances.According to the latest information, AWS Inferentia and Trainium instance prices range from $0.228 per hour for an inf1.xlarge instance to $24.78 per hour for a trn1n.32xlarge instance. The cheapest Inferentia instance is the inf1.xlarge at $0.228 per hour, while the most expensive is the inf2.48xlarge at $12.9813 per hour. The cheapest Trainium instance is the trn1.2xlarge at $1.3438 per hour, while the most expensive is the trn1n.32xlarge at $24.78 per hour.”
Before you create your agent, you should set up action groups and knowledge bases that you want to add to your agent:
Action groups define the tasks that you want your agent to help customers carry out.
Knowledge bases provide a repository of information that the agent can query to answer customer queries and improve its generated responses. For more information, see Knowledge bases for Amazon Bedrock.
After you complete the AWS CDK deployment, you can verify your agent along with its corresponding knowledge base and action group by completing the following steps:
On the Amazon Bedrock console, choose Agents in the navigation pane.
Choose the name of your agent.
Choose the working draft.
You can review the action group and knowledge base in the working draft.
Knowledge Bases for Amazon Bedrock
Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow (managed RAG), from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources and manage data flows. For this post, we created a knowledge base for Amazon Bedrock using the AWS CDK; it’s based on the database of EC2 instance documentation stored in an S3 bucket.
Action groups
An action group consists of the following components that you set up:
An OpenAPI schema that defines the APIs that your action group should call. Your agent uses the API schema to determine the fields it needs to elicit from the customer to populate for the API request.
A Lambda function that defines the business logic for the action that your agent will carry out.
For each action group in an agent, you define a Lambda function to program the business logic for carrying out an action group and customize how you want the API response to be returned. You use the variables from the input event to define your functions and return a response to the agent. In our use case, we used Amazon Bedrock FMs, converting text into SQL queries with specified constraints. This process empowers the extraction of data from Athena tables, effectively addressing inquiries related to data.
The following screenshot shows an Athena table and sample query.
Sample questions and answers
After the AWS CDK deployment is complete, you can either test the agent on the Amazon Bedrock console or through the Streamlit app URL listed in the outputs of the chatbot stack on the AWS CloudFormation console, as shown in the following screenshot.
In the UI of the chatbot, you can view the source of the response. If the response comes from the knowledge base, you will see a link related to the documentation. If the response is sourced from the Amazon EC2 pricing table, you will see the SQL query text converted from the relevant table. The chatbot is also capable of answering questions that require information from both data sources. The following screenshots show some sample questions and answers with different data sources.
Each response from an Amazon Bedrock agent is accompanied by a trace that details the steps being orchestrated by the agent. The trace helps you follow the agent’s reasoning process that leads it to the response it gives at that point in the conversation.
When you show the trace in the test window in the console, a window appears showing a trace for each step in the reasoning process. You can view each step of the trace in real time as your agent performs orchestration. Each step can be one of the following traces:
PreProcessingTrace – Traces the input and output of the preprocessing step, in which the agent contextualizes and categorizes user input and determines if it is valid
OrchestrationTrace – Traces the input and output of the orchestration step, in which the agent interprets the input, invokes APIs and queries knowledge bases, and returns output to either continue orchestration or respond to the user
PostProcessingTrace – Traces the input and output of the postprocessing step, in which the agent handles the final output of the orchestration and determines how to return the response to the user
FailureTrace – Traces the reason that a step failed
Customizations for your own dataset
To integrate your custom data into the solution, follow the structured guidelines in this section and tailor them to your requirements. These steps are designed to provide a seamless and efficient integration process, enabling you to deploy the solution effectively with your own data.
Integrate knowledge base data
To prepare your data for integration, locate the assets/knowledgebase_data_source/ directory and place your dataset within this folder.
To make configuration adjustments, access the cdk.json file. Navigate to the context/config/paths/knowledgebase_file_name field and update it accordingly. Furthermore, modify the context/config/bedrock_instructions/knowledgebase_instruction field in the cdk.json file to accurately reflect the nuances and context of your new dataset.
Integrate structural data
To organize your structural data, within the assets/data_query_data_source/ directory, create a subdirectory (for example, tabular_data). Deposit your structured dataset (acceptable formats include CSV, JSON, ORC, and Parquet) into this newly created subfolder.
For configuration and code updates, make the following changes:
Update the cdk.json file’s context/config/paths/athena_table_data_prefix field to align with the new data path
Revise code/action-lambda/dynamic_examples.csv by incorporating new text to SQL examples that correspond with your dataset
Revise code/action-lambda/prompt_templates.py to mirror the attributes of your new tabular data
Modify the cdk.json file’s context/config/bedrock_instructions/action_group_description field to elucidate the purpose and functionality of the action Lambda function tailored for your dataset
Reflect the new functionalities of your action Lambda function in the assets/agent_api_schema/artifacts_schema.json file
General updates
In the cdk.json file, under the context/config/bedrock_instructions/agent_instruction section, provide a comprehensive description of the intended functionality and design purpose for your agents, taking into account the newly integrated data.
Clean up
To delete your resources when you’re finished using the solution and to avoid future costs, you can either delete the stack on the AWS CloudFormation console or run the following command in the terminal:
Conclusion
In this post, we illustrated the process of using the AWS CDK to establish and oversee a set of AWS resources designed to construct a chatbot on Amazon Bedrock. If you’re interested in connecting to your data source and developing your own chatbot, you can begin exploring with Amazon Bedrock.
About the Authors
Jundong Qiao is a Machine Learning Engineer at AWS Professional Service, where he specializes in implementing and enhancing AI/ML capabilities across various sectors. His expertise encompasses building next-generation AI solutions, including chatbots and predictive models that drive efficiency and innovation. Prior to AWS, Jundong was an Engineering Manager in Machine Learning at ACV Auctions, where he led initiatives that leveraged AI/ML to address intricate issues within the automotive industry.
Kara Yang is a data scientist at AWS Professional Services, adept at leveraging cloud computing, machine learning, and Generative AI to tackle diverse industry challenges. Passionately dedicated to innovation, she consistently pursues new technologies, refines solutions, and delights in sharing her expertise through writing and presentations.
Kiowa Jackson is a Machine Learning Engineer at AWS ProServe, dedicated to helping customers leverage Generative AI for creating and deploying novel applications. He is passionate about placing the benefits of GenAI in the hands of users through real-world use cases.
Praveen Kumar Jeyarajan is a Principal DevOps Consultant at AWS, supporting Enterprise customers and their journey to the cloud. He has 13+ years of DevOps experience and is skilled in solving myriad technical challenges using the latest technologies. He holds a Masters degree in Software Engineering. Outside of work, he enjoys watching movies and playing tennis.
Shuai Cao is a Senior Data Science Manager focused on Generative AI at Amazon Web Services. He leads teams of data scientists, machine learning engineers, and application architects to deliver AI/ML solutions for customers. Outside of work, he enjoys composing and arranging music.

Build private and secure enterprise generative AI apps with Amazon Q Business and AWS IAM Identity Center
As of April 30, 2024 Amazon Q Business is generally available. Amazon Q Business is a conversational assistant powered by generative artificial intelligence (AI) that enhances workforce productivity by answering questions and completing tasks based on information in your enterprise systems. Your employees can access enterprise content securely and privately using web applications built with Amazon Q Business. The success of these applications depends on two key factors: first, that an end-user of the application is only able to see responses generated from documents they have been granted access to, and second, that each user’s conversation history is private, secure, and accessible only to the user.
Amazon Q Business operationalizes this by validating the identity of the user every time they access the application so that the application can use the end-user’s identity to restrict tasks and answers to documents that the user has access to. This outcome is achieved with a combination of AWS IAM Identity Center and Amazon Q Business. IAM Identity Center stores the user identity, is the authoritative source of identity information for Amazon Q Business applications, and validates the user’s identity when they access an Amazon Q Business application. You can configure IAM Identity Center to use your enterprise identity provider (IdP)—such as Okta or Microsoft Entra ID—as the identity source. Amazon Q Business makes sure that access control lists (ACLs) for enterprise documents being indexed are matched to the user identities provided by IAM Identity Center, and that these ACLs are honored every time the application calls Amazon Q Business APIs to respond to user queries.
In this post, we show how IAM Identity Center acts as a gateway to steer user identities created by your enterprise IdP as the identity source, for Amazon Q Business, and how Amazon Q Business uses these identities to respond securely and confidentially to user queries. We use an example of a generative AI employee assistant built with Amazon Q Business, demonstrate how to set it up to only respond using enterprise content that each employee has permissions to access, and show how employees are able to converse securely and privately with this assistant.
Solution overview
The following diagram shows a high-level architecture of how the enterprise IdP, IAM Identity Center instance, and Amazon Q Business application interact with each other to enable an authenticated user to securely and privately interact with an Amazon Q Business application using an Amazon Q Business web experience from their web browser.
When using an external IdP such as Okta, users and groups are first provisioned in the IdP and then automatically synchronized with the IAM Identity Center instance using the SCIM protocol. When a user starts the Amazon Q Business web experience, they are authenticated with their IdP using single sign-on, and the tokens obtained from the IdP are used by Amazon Q Business to validate the user with IAM Identity Center. After validation, a chat session is started with the user.
The sample use case in this post uses an IAM Identity Center account instance with its identity source configured as Okta, which is used as the IdP. Then we ingest content from Atlassian Confluence. The Amazon Q Business built-in connector for Confluence ingests the local users and groups configured in Confluence, as well as ACLs for the spaces and documents, to the Amazon Q Business application index. These users from the data source are matched with the users configured in the IAM Identity Center instance, and aliases are created in Amazon Q Business User Store for correct ACL enforcement.
Prerequisites
To implement this solution for the sample use case of this post, you need an IAM Identity Center instance and Okta identity provider as identity source. We provide more information about these resources in this section.
IAM Identity Center instance
An Amazon Q Business application requires an IAM Identity Center instance to be associated with it. There are two types of IAM Identity Center instances: an organization instance and an account instance. Amazon Q Business applications can work with either type of instance. These instances store the user identities that are created by an IdP, as well as the groups to which the users belong.
For production use cases, an IAM Identity Center organization instance is recommended. The advantage of an organization instance is that it can be used by an Amazon Q Business application in any AWS account in AWS Organizations, and you only pay once for a user in your company, if you have multiple Amazon Q Business applications spread across several AWS accounts and you use organization instance. Many AWS enterprise customers use Organizations, and have IAM Identity Center organization instances associated with them.
For proof of concept and departmental use cases, or in situations when an AWS account is not part of an AWS Organization and you don’t want to create a new AWS organization, you can use an IAM Identity Center account instance to enable an Amazon Q Business application. In this case, only the Amazon Q Business application configured in the AWS account in which the account instance is created will be able to use that instance.
Amazon Q Business implements a per-user subscription fee. A user is billed only one time if they are uniquely identifiable across different accounts and different Amazon Q Business applications. For example, if multiple Amazon Q Business applications are within a single AWS account, a user that is uniquely identified by an IAM Identity Center instance tied to this account will only be billed one time for using these applications. If your organization has two accounts, and you have an organization-level IAM Identity Center instance, a user who is uniquely identified in the organization-level instance will be billed only one time even though they access applications in both accounts. However, if you have two account-level IAM Identity Center instances, a user in one account can’t be identified as the same user in another account because there is no central identity. This means that the same user will be billed twice. We therefore recommend using organization-level IAM Identity Center instances for production use cases to optimize costs.
In both these cases, the Amazon Q Business application needs to be in the same AWS Region as the IAM Identity Center instance.
Identity source
If you already use an IdP such as Okta or Entra ID, you can continue to use your preferred IdP with Amazon Q Business applications. In this case, the IAM Identity Center instance is configured to use the IdP as its identity source. The users and user groups from the IdP can be automatically synced to the IAM Identity Center instance using SCIM. Many AWS enterprise customers already have this configured for their IAM Identity Center organization instance. For more information about all the supported IdPs, see Getting started tutorials. The process is similar for IAM Identity Center organization instances and account instances.
AWS IAM Identity Center instance configured with Okta as the identity source
The following screenshot shows the IAM Identity Center application configured in Okta, and the users and groups from the Okta configuration assigned to this application.
The following screenshot shows the IAM Identity Center instance user store after configuring Okta as the identity source. Here the user and group information is automatically provisioned (synchronized) from Okta into IAM Identity Center using the System for Cross-domain Identity Management (SCIM) v2.0 protocol.
Configure an Amazon Q Business application with IAM Identity Center enabled
Complete the following steps to create an Amazon Q Business application and enable IAM Identity Center:
On the Amazon Q Business console, choose Create application.
For Application name, enter a name.
Unless you need to change the AWS Identity and Access Management (IAM) role for the application or customize encryption settings, keep the default settings.
Choose Create.
On the Select retriever page, unless you want to configure a preexisting Amazon Kendra index as a retriever, or you need to configure storage units for more than 20,000 documents, you can continue with the default settings.
Choose Next.
For more information about Amazon Q Business retrievers, refer to Creating and selecting a retriever for an Amazon Q Business application.
On the Connect data sources page, for Data sources, choose Confluence.
The following instructions demonstrate how to configure the Confluence data source. These may differ for other data sources.
For Data source name, enter a name.
For Source¸ select Confluence Cloud.
For Confluence URL, enter the Confluence URL.
For Authentication, select Basic authentication.
For AWS Secrets Manager secret, choose an AWS Secrets Manager secret.
For Virtual Private Cloud, choose No VPC.
For IAM role, choose Create a new service role.
For Role name¸ either go with the provided name or edit it for your new role.
For Sync scope, select the contents to sync.
For Sync mode, select Full sync.
For Frequency, choose Run on demand.
For Field mappings, leave the defaults.
Choose Add data source.
Choose Next.
On the Add groups and users page, choose Add groups and users.
In the pop-up window, choose Get started.
Search for users based on their display name or groups, then choose the user or group you want to add to the application.
Add more users as needed.
Choose Assign.
You will see the following screen:
Choose subscription for each user by clicking on the Choose subscription pull down and then selecting the check mark.
After choosing subscription for all the users, your screen will look as below. Unless you want to change the service role, choose Create application.
After the application is created, you will see the application settings page, as shown in the following screenshot.
Employee AI assistant use case
To illustrate how you can build a secure and private generative AI assistant for your employees using Amazon Q Business applications, let’s take a sample use case of an employee AI assistant in an enterprise corporation. Two new employees, Mateo Jackson and Mary Major, have joined the company on two different projects, and have finished their employee orientation. They have been given corporate laptops, and their accounts are provisioned in the corporate IdP. They have been told to get help from the employee AI assistant for any questions related to their new team member activities and their benefits.
The company uses Confluence to manage their enterprise content. The sample Amazon Q application used to run the scenarios for this post is configured with a data source using the built-in connector for Confluence to index the enterprise Confluence spaces used by employees. The example uses three Confluence spaces: AnyOrgApp Project, ACME Project Space, and AJ-DEMO-HR-SPACE. The access permissions for these spaces are as follows:
AJ-DEMO-HR-SPACE – All employees, including Mateo and Mary
AnyOrgApp Project – Employees assigned to the project including Mateo
ACME Project Space – Employees assigned to the project including Mary
Let’s look at how Mateo and Mary experience their employee AI assistant.
Both are provided with the URL of the employee AI assistant web experience. They use the URL and sign in to the IdP from the browsers of their laptops. Mateo and Mary both want to know about their new team member activities and their fellow team members. They ask the same questions to the employee AI assistant but get different responses, because each has access to separate projects. In the following screenshots, the browser window on the left is for Mateo Jackson and the one on the right is for Mary Major. Mateo gets information about the AnyOrgApp project and Mary gets information about the ACME project.
Mateo chooses Sources under the question about team members to take a closer look at the team member information, and Mary choosing Sources under the question for new team member onboarding activities. The following screenshots show their updated views.
Mateo and Mary want to find out more about the benefits their new job offers and how the benefits are applicable to their personal and family situations.
The following screenshot shows that Mary asks the employee AI assistant questions about her benefits and eligibility.
Mary can also refer to the source documents.
The following screenshot shows that Mateo asks the employee AI assistant different questions about his eligibility.
Mateo looks at the following source documents.
Both Mary and Mateo first want to know their eligibility for benefits. But after that, they have different questions to ask. Even though the benefits-related documents are accessible by both Mary and Mateo, their conversations with employee AI assistant are private and personal. The assurance that their conversation history is private and can’t be seen by any other user is critical for the success of a generative AI employee productivity assistant.
Clean up
If you created a new Amazon Q Business application to try out the integration with IAM Identity Center, and don’t plan to use it further, unsubscribe and remove assigned users from the application and delete it so that your AWS account does not accumulate costs.
To unsubscribe and remove users go to the application details page and select Manage access and subscriptions.
Select all the users, and then use the Edit button to choose Unsubscribe and remove as shown below.
Delete the application after removing the users, going back to the application details page and selecting Delete.
Conclusion
For enterprise generative AI assistants such as the one shown in this post to be successful, they must respect access control as well as assure the privacy and confidentiality of every employee. Amazon Q Business and IAM Identity Center provide a solution that authenticates each user and validates the user identity at each step to enforce access control along with privacy and confidentiality.
To achieve this, IAM Identity Center acts as a gateway to sync user and group identities from an IdP (such as Okta), and Amazon Q Business uses IAM Identity Center-provided identities to uniquely identify a user of an Amazon Q Business application (in this case, an employee AI assistant). Document ACLs and local users set up in the data source (such as Confluence) are matched up with the user and group identities provided by IAM Identity Center. At query time, Amazon Q Business answers questions from users utilizing only those documents that they are provided access to by the document ACLs.
If you want to know more, take a look at the Amazon Q Business launch blog post on AWS News Blog, and refer to Amazon Q Business User Guide. For more information on IAM Identity Center, refer to the AWS IAM Identity Center User Guide.
About the Authors
Abhinav Jawadekar is a Principal Solutions Architect in the Amazon Q Business service team at AWS. Abhinav works with AWS customers and partners to help them build generative AI solutions on AWS.
Venky Nagapudi is a Senior Manager of Product Management for Q Business, Amazon Comprehend and Amazon Translate. His focus areas on Q Business include user identity management, and using offline intelligence from documents to improve Q Business accuracy and helpfulness.

Enhance customer service efficiency with AI-powered summarization using Amazon Transcribe Call Analytics
In the fast-paced world of customer service, efficiency and accuracy are paramount. After each call, contact center agents often spend up to a third of the total call time summarizing the customer conversation. Additionally, manual summarization can lead to inconsistencies in the style and level of detail due to varying interpretations of note-taking guidelines. This post-contact work can not only add to customer wait times, but also can put pressure on some agents to avoid taking notes altogether. Supervisors also spend a considerable amount of time listening to call recordings or reading transcripts to understand the gist of a customer conversation when investigating customer issues or evaluating an agent’s performance. This can make it challenging to scale quality management within the contact center.
To address these issues, we launched a generative artificial intelligence (AI) call summarization feature in Amazon Transcribe Call Analytics. Transcribe Call Analytics is a generative AI-powered API for generating highly accurate call transcripts and extracting conversation insights to improve customer experience, agent productivity, and supervisor productivity. Powered by Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) through a single API, generative call summarization in Transcribe Call Analytics produces call summaries that reduce the time agents spend capturing and summarizing notes after each conversation. This reduces customer wait times and improves agent productivity. Generative call summarization also provides supervisors with quick insight into a conversation without the need to listen to the entire call recording or read the entire transcript.
As Praphul Kumar, Chief Product Officer at SuccessKPI, noted,
“Generative call summarization in the Amazon Transcribe Call Analytics API has enabled us to add generative AI capabilities to our platform faster. With this feature, we are able to improve productivity in our customer’s contact center by automatically summarizing calls and removing the need for agents to write after call notes. We are looking forward to bringing this valuable capability into the hands of many more large enterprises.”
We previously published Use generative AI to increase agent productivity through automated call summarization. This new generative call summarization feature automatically integrates with multiple services and handles necessary configurations, making it simple and seamless to start using and realizing the benefits. You don’t need to manually integrate with services or perform additional configurations. Simply turn the feature on from the Amazon Transcribe console or using the start_call_analytics_job API. You can also use generative call summarization through Amazon Transcribe Post Call Analytics Solution for post-call summaries.
In this post, we show you how to use the new generative call summarization feature.
Solution overview
The following diagram illustrates the solution architecture.
You can upload a call recording in Amazon S3 and start a Transcribe Call Analytics job. The summary is generated and uploaded back to S3 along with the transcript and analytics as a single JSON.
We show you how to use the generative call summarization feature with a call sample inquiring about a used car through the following high-level steps:
Create a new Post Call Analytics job and turn on the generative call summarization feature.
Review the generative call summarization results.
Prerequisites
To get started, upload your recorded file or the sample file provided to an Amazon Simple Storage Service (Amazon S3) bucket.
Create a new Post call analytics job
Complete the following steps to create a new Post call analytics job:
On the Amazon Transcribe console, choose Post-call Analytics in the navigation pane under Amazon Transcribe Call Analytics.
Choose Create job.
For Name, enter summarysample.
In the Language settings and Model type sections, leave the default settings.
For Input file location on S3, browse to the S3 bucket containing the uploaded audio file and choose Choose.
In the Output data section, leave as default.
Create a new AWS Identity and Access Management (IAM) role named summarysamplerole that provides Amazon Transcribe service permissions to read the audio files from the S3 bucket.
In the Role permissions details section, leave as default and choose Next.
Toggle Generative call summarization on and choose Create job.
Review the transcription and summary
When the status of the job is Complete, you can review the transcription and summary by choosing the job name summarysample. The Text tab shows the Agent and Customer sentences clearly separated.
The Generative call summarization tab provides a concise summary of the call.
Choose Download transcript for the JSON output containing the transcript and summary.
Conclusion
The world of customer service is constantly evolving, and organizations must adapt to meet the growing demands of their clients. Amazon Transcribe Call Analytics introduces an innovative solution to streamline the post-call process and enhance productivity. With generative call summarization, contact center agents can devote more time to engage with customers, and supervisors can gain insights quickly without extensive call reviews. This feature improves efficiency and empowers enterprises to scale their quality management efforts, enabling them to deliver exceptional customer experiences.
Generative call summarization in Amazon Transcribe Call Analytics is generally available today in English in US East (N. Virginia) and US West (Oregon). We invite you to share your thoughts and questions in the comments section.
Learn more:
Amazon Transcribe Call Analytics product page
Amazon Transcribe Call Analytics pricing page
Amazon Transcribe Call Analytics developer guide
About the Authors
Ami Dani is a Senior Technical Program Manager at AWS focusing on AI/ML services. During her career, she has focused on delivering transformative software development projects for the federal government and large companies in industries as diverse as advertising, entertainment, and finance. Ami has experience driving business growth, implementing innovative training programs and successfully managing complex, high-impact projects. She is a strategic problem-solver and collaborative partner, consistently delivering results that exceed expectations.
Gopikrishnan Anilkumar is a Senior Technical Product Manager on the Amazon Transcribe team. He has 10 years of product management experience across a variety of domains and is passionate about AI/ML. Outside of work, Gopikrishnan loves to travel and enjoys playing cricket.
Trotting robots reveal emergence of animal gait transitions
A four-legged robot trained with machine learning has learned to avoid falls by spontaneously switching between walking, trotting, and pronking — a milestone for roboticists as well as biologists interested in animal locomotion.

Amazon Q Business and Amazon Q in QuickSight empowers employees to be more data-driven and make better, faster decisions using company knowledge
Today, we announced the General Availability of Amazon Q, the most capable generative AI powered assistant for accelerating software development and leveraging companies’ internal data. “During the preview, early indications signaled Amazon Q could help our customers’ employees become more than 80% more productive at their jobs; and with the new features we’re planning on introducing in the future, we think this will only continue to grow,” shared Dr. Swami Sivasubramanian, vice president of Artificial Intelligence and Data at AWS. Employees across every organization collectively spend hours every week searching internal sources for information, piecing together analyses, writing reports, building presentations, creating and searching for insights in dashboards, or adapting content for different customers or audiences. We built Amazon Q Business and Amazon Q in QuickSight to make this much simpler.
Amazon Q Business is a generative AI–powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. It empowers employees to be more creative, data-driven, efficient, prepared, and productive.
Amazon Q Business unites more data sources than any other generative AI assistant available today
Amazon Q Business easily and securely connects to 40+ commonly used business tools, such as wikis, intranets, Atlassian, Gmail, Microsoft Exchange, Salesforce, ServiceNow, Slack, and Amazon Simple Storage Service (Amazon S3)–more than any other generative AI assistant available today. Simply point Q at your enterprise data repositories, and it will search all of your data, summarize logically, analyze trends, and engage in dialog with end users about the data. This helps business users to access all of their data, no matter where it resides in their organization. Watch use cases of Amazon Q Business through its simple web base interface.
Built from the ground up with security and privacy in mind
Amazon Q Business is built to be secure and private by design. It seamlessly integrates with a customer’s existing identities, roles, and access permissions to personalize the interactions for each individual user, while maintaining the highest levels of security. It generates accurate responses based on enterprise information, and customers can restrict sensitive topics, block keywords, and filter out inappropriate content and does not use customer content to train the underlying model for anybody else. If you want to learn more about how to set up and administer Q Business, check out the News Blog: Amazon Q Business.
Generative BI allows analysts and business users to build detailed dashboards in minutes
Amazon QuickSight is AWS’s unified Business Intelligence (BI) service built for the cloud. With Amazon Q in QuickSight, customers get a Generative BI assistant that allows business analysts to use natural language to build BI dashboards in minutes and easily create visualizations and complex calculations. It is also the only BI product where business users can get AI-driven executive summaries of dashboards, ask questions of data beyond what is presented in the dashboards–for instant answers, and create detailed and customizable data stories highlighting key insights, trends, and drivers. Business users can ask to “build a story about how the business has changed over the last month for a business review with leadership” and in seconds Amazon Q creates a story in multiple parts explaining different aspects of their data with specific insights and supporting visuals, including specific ideas of how to improve the business. Users can choose to layout content in an easy to share document or presentation where they can customize text, images, and themes, and use Amazon Q to rewrite and improve the text. You can read more about all the updates to Amazon QuickSight at the AWS Business Intelligence Blog, and watch the Unlock the power of Generative BI with Amazon Q in QuickSight on creating and sharing content based on your own data.
First-of-its-kind capability that helps every employee go from conversation to generative AI-powered app in seconds
Today, we announced a new capability of Amazon Q Business, called Amazon Q Apps (in preview) that allows employees to easily and quickly create generative AI-powered apps based on their company data, without requiring any prior coding experience. With Amazon Q Apps, employees simply describe the app they want, in natural language, or they can take an existing conversation where Amazon Q Business helped them solve a problem and, with one click, Amazon Q will instantly generate an app that accomplishes their desired task that can be easily shared across their organization.
For example, generating employee onboarding plans for new recruits can be a long and laborious process. They require many hours of searching through different data stores and documents to find the appropriate content for the new employee and oftentimes the content is out of date or not specific enough to their role. With Amazon Q, an HR professional can simply describe an app that could pull together a personalized onboarding plan for a new employee, simply by inputting their name and employee ID. In a matter of seconds, Amazon Q Apps will build an app that can automatically generate a personalized onboarding plan tailored to the employee, their role, and the department using the latest data. The HR professional can then share the app with hiring managers across the company to instantly build personalized onboarding plans for their own teams. Now, with Amazon Q Apps, business users can easily, quickly, and securely build an app based on enterprise information to improve their work productivity. Watch the Introducing Amazon Q Apps to see how easy it is to implement.
Bani Bedi, senior vice president, Corporate Development and Strategy at Smartsheet, said:
“Amazon Q Business is streamlining knowledge management and accelerating employee productivity at Smartsheet. Previously, it was too difficult for our 3,300 employees to find the information they needed across public help documents, training courses, and hundreds of all-employee Slack help channels. We have consolidated our organizational knowledge into a single AI engine to give our workforce immediate answers, significantly boosting employee productivity.”
You can hear more in the interview AWS Fireside Chat with Smartsheet.
We’re really excited to share Amazon Q Business and Amazon Q in QuickSight with you. If you want more information on generative AI at AWS, you can find it AWS Generative AI.
About the Authors
Mukesh Karki is GM of Amazon Q Business.
Tracy Daugherty is GM of Amazon Quicksight.
